
다음 그래프에 있는 데이터 포인트를 가지고 있다고 가정하자. 이 데이터에 직선 또는 곡선을 학습시켜 새로운 포인트에 대한 예측을 만들어야 한다.
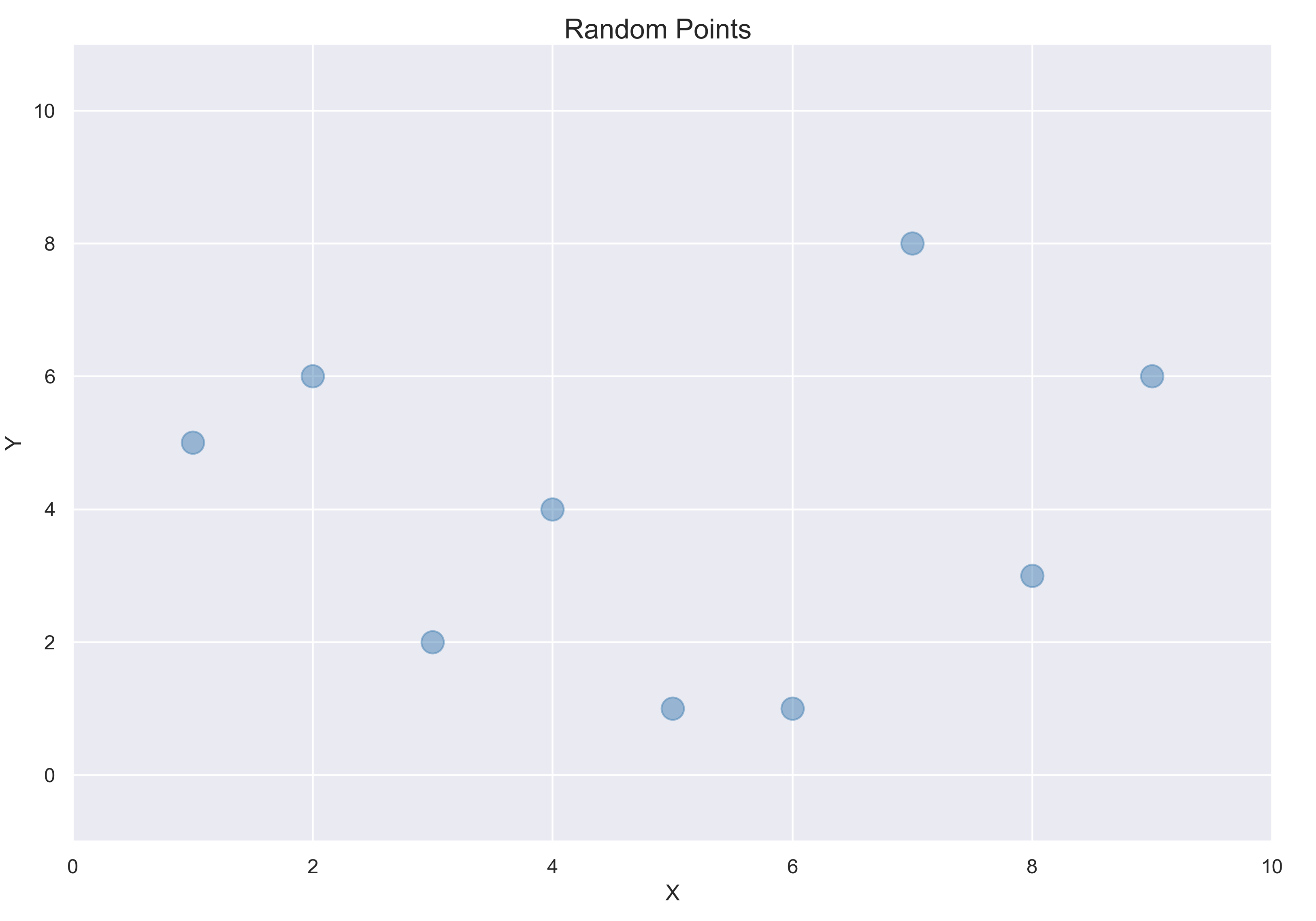 랜덤한 포인트들의 그래프
랜덤한 포인트들의 그래프
3.1 선형 회귀
각 점들과 직선 사이의 거리 제곱을 최소화하는 선형회귀를 사용한다.
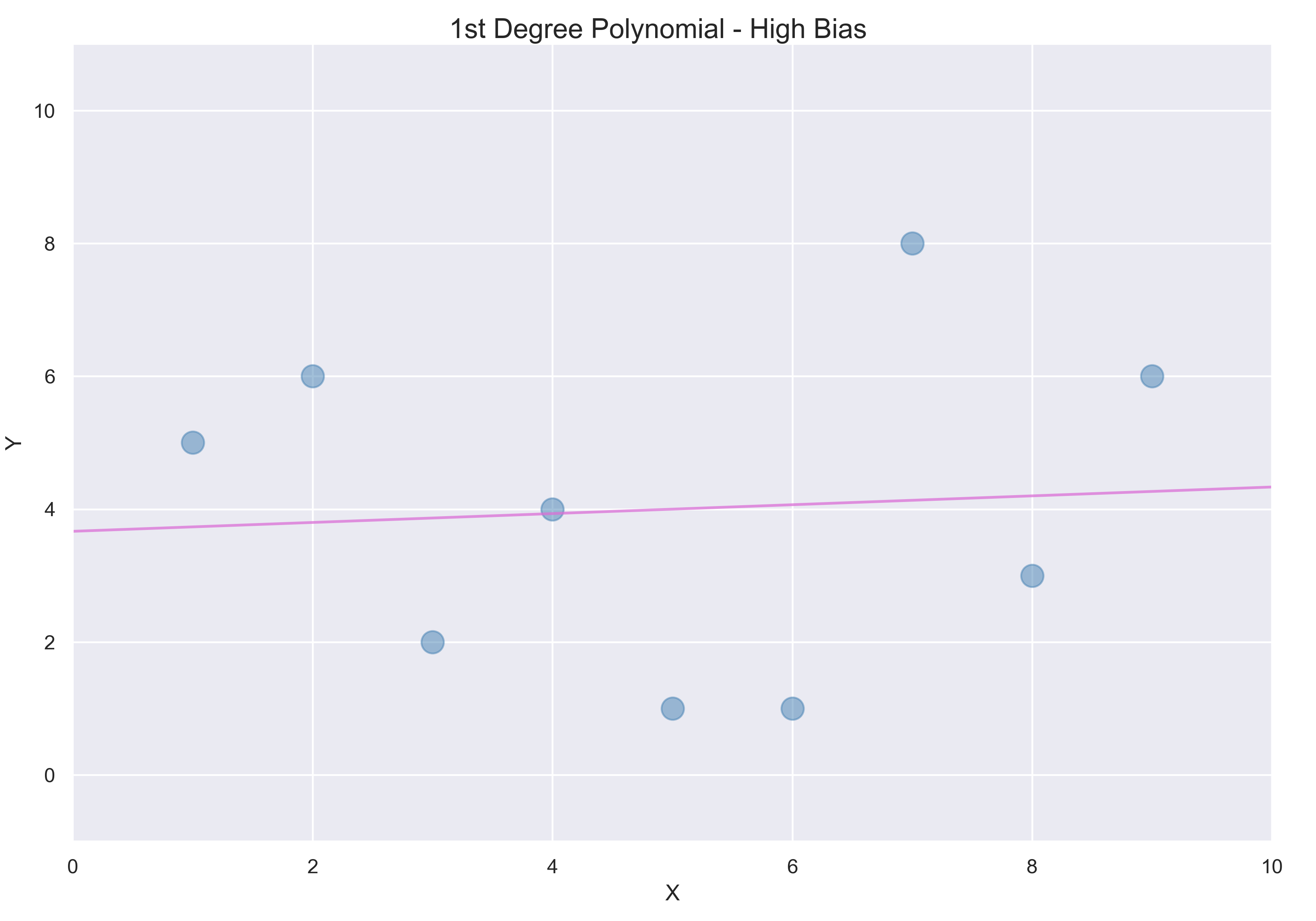
직선은 일반적으로 편향이 크다. 머신러닝에서 편향은 모델을 실제 문제에 적용할 때 오차를 예측하는 데서 유래한다. 예측이 직선에 제한되어 있고 데이터 변화를 고려하지 못하기 때문에 편향이 크다고 할 수있다.
많은 경우 직선은 정확한 예측을 하기에 충분히 복잡하지 않다. 이런 경우에 머신러닝 모델이 편향이 높고 데이터에 과소적합되었다고 말한다.
3.2 8차 다항식
다음과 같이 8차 다항식을 적용한다. 포인트가 9개이기 때문에 완벽하게 주어진 데이터에 적합시킬 수있다.

이런 경우에 분산이 높다고 할 수 있겠다. 머신러닝에서 분산은 다른 훈련 데이터가 주어졌을 때 모델이 얼마나 변화하는지 나타내는 용어이다. 분산은 확률 변수와 평균 사이의 차이를 제곱한 것이다. 아홉 개의 새로운 데이터 포인트가 훈련 세트로 주어지면 위의 8차 다항식은 완전히 다른 모양으로 바뀔것이다. 따라서 분산이 높다.
분산이 높은 모델은 데이터에 과대적합되기 쉽다. 이런 모델은 훈련 데이터에 너무 밀접하게 맞춰져 있기 때문에 새로운 데이터 포인트에 잘 일반화되지 못한다.
3.3 3차 다항식
마지막으로 3차 다항식을 적용해본다.
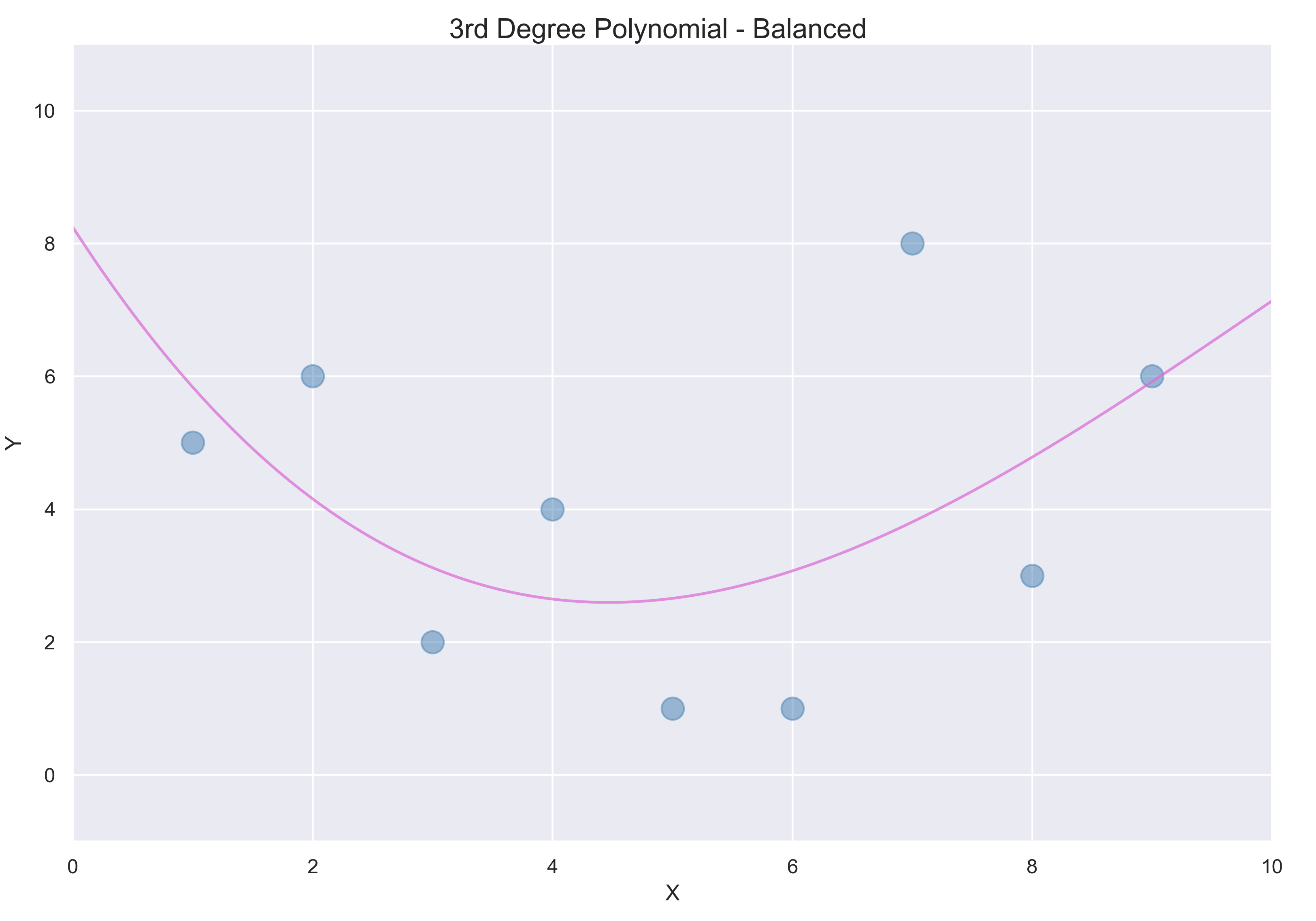
이 3차 다항식은 분산과 편향 사이에 균형이 잘 잡혀있다. 일반적인 곡선의 형태를 따르면서 변동에 적응한다.
분산과 편향의 균형
낮은 분산은 훈련 세트가 달라져도 크게 다른 곡선을 만들지 않는다는 뜻이다. 낮은 편향은 이 모델을 실전에 적용했을 때 오차가 너무 크지 않다는 뜻이다. 머신러닝에서 낮은 분산과 편향을 가지는 것이 이상적이다.
분산과 편향 사이에 균형을 잘 잡기 위한 가장 좋은 머신러닝 방법 중 하나는 하이퍼파라미터 튜닝 이다.