
인코더와 디코더를 포함한 완전한 모양의 트랜스포머 아키텍처는 다음과 같다.
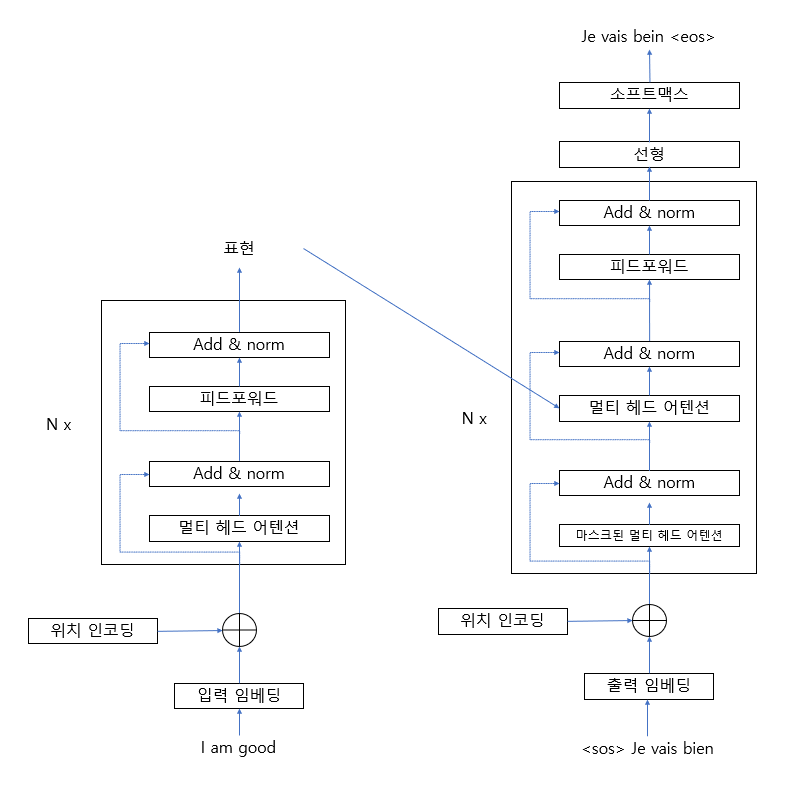 그림 1-63 트랜스포머 인코더, 디코더
그림 1-63 트랜스포머 인코더, 디코더
$N \times$ 는 인코더와 디코더를 $N$개 쌓을 수 있음으로 나타낸다. [그림 1-63]에서 알 수 있듯이, 입력 문장 (소스 문장)을 입력하면 인코더에서는 해당 문장에 대한 표현을 학습시키고, 그 결괏값을 디코더에 보내면 디코더에서 타깃 문장을 생성한다.
1.5 트랜스포머 학습
손실 함수 (loss function)을 최소화하는 방향으로 트랜스포머 네트워크를 학습시킬 수 있다. 이때 어떤 손실 함수를 사용해야 할까? 디코더가 vocab에 대한 확률 분포를 예측하고 확률이 가장 큰 단어를 선택한다는 것을 배웠다. 즉, 올바른 문장을 생성하려면 예측 확률 분포와 실제 확률 분포 사이의 차이를 최소화해야 한다. 그러려면 두 분포의 차이를 알아야 한다. 이때 교차 엔트로피 (cross entropy)를 사용하면 분포의 차이를 알 수 있다. 따라서 손실 함수를 교차 엔트로피 손실 (cross-entropy loss)로 정의하고 예측 확률 분포와 실제 확률 분포를 최소화하도록 모델을 학습한다. 이때 옵티마이저 (optimizer)는 아담 (Adam)을 사용한다.
여기서 한 가지 고려할 점은 overfitting을 방지하려면 각 서브레이어의 출력에 드롭아웃을 적용하고, 임베딩 및 위치 인코딩의 합을 구할 때도 드롭아웃을 적용해야 한다는 것이다.
1.6 마치며
이번 장에서는 트랜스포머 모델이 무엇인지, 인코더-디코더 아키텍처가 어떤 원리로 작동하는지를 다뤘다. 트랜스포머의 인코더 부분을 살펴보면서 멀티 헤드 어텐션과 피드 포워드 네트워크 같은 인코더에서 사용하는 다양한 서브레이어를 확인했다.
셀프 어텐션은 단어를 좀 더 잘 이해하기 위해 주어진 문장의 모든 단어와 해당 단어를 연결하는 형태다. 셀프 어텐션을 계산하기 위해 쿼리, 키, 밸류 행렬이라는 세 가지 행렬을 사용했다. 그 다음으로 위치 인코딩을 계산하는 방법과 위치 인코딩을 사용해 문장 내 단어의 순서를 입력하는 방법도 살펴봤다. 인코더에서 피드포워드 네트워크가 작동하는 방법과 add 및 norm 요소에 대해서도 배웠다.
인코더에 대해 알아본 다음 디코더의 작동 원리를 살펴봤다. 마스크된 멀티 헤드 어텐션, 인코더-디코더 어텐션, 피드포워드 네트워크 등 디코더에서 사용하는 서브레이어를 알아봤다. 트랜스포머의 인코더와 디코더가 결합한 형태에서 어떻게 작동하는지 이해한 다음 네트워크를 학습시키는 방법도 배웠다.