
이미 단일 결정 트리의 매개변수를 알아보았기 때무에 랜덤 포레스트에서 다룰 매개변수는 아주 많지 않다.
여기서는 랜덤 포레스트에 추가된 매개변수를 먼저 살펴보고 이전 장에서 보았던 매개변수를 그룹으로 묶어서 알아볼 것이다. 이러한 매개변수는 XGBoost에서도 많이 사용된다.
3.1 oob_score
OOB는 Out of bag의 줄임말이다.
랜덤 포레스트는 중복을 허용한 샘플링인 배깅을 통해 결정 트리를 만들기 때문에, 모든 샘플 중에 일부 샘플은 선택되지 않고 남아 있게 된다.
이런 샘플을 테스트 세트로 사용할 수 있다. oob_score=True로 설정하면 랜덤 포레스트 모델을 훈련한 후 각 트리에서 사용되지 않은 샘플을 사용해 개별 트리의 예측 점수를 누적하여 평균을 낸다.
다른 말로 하면 oob_score 매개변수는 테스트 점수의 대안을 제시하는 것이다. 모델을 훈련한 후 OOB점수를 바로 출력할 수 있다.
인구 조사 데이터셋에 oob_score 매개변수를 적용해보았다. oob_score 매개변수를 사용하여 모델을 테스트하였기 때문에 여기에서는 편의상 데이터를 훈련 세트와 데이터 세트로 나누지 않을 것이다.
1
2
3
rf = RandomForestClassifier(oob_score=True, n_estimators=10, random_state=2, n_jobs=-1)
rf.fit(X_census, y_census)
print(rf.oob_score_)
0.8343109855348423
데이터 1을 사용하지 않은 DT = {DT1, DT3, DT6}
데이터 1의 대한 각각의 예측확률 = {DT1: 0.7, DT3: 0.6, DT6: 0.5}
랜덤 포레스트의 최종 에측확률: 0.6
위 과정을 반복 ⇒ OOB Score!
그러나 여기에서 처럼 랜덤 포레스트의 개별 트리 개수가 작을 경우 정확도를 높이기 위해 수집할 OOB 샘플의 개수가 충분하지 않다.
더 많은 트리는 더 많은 샘플을 의미하고 종종 정확도를 높인다.
3.2 n_estimators
랜덤 포레스트는 많은 트리를 앙상블 했을 때 강력한 성능 을 발휘한다. 얼마나 많아야 할까? 사이킷-런==0.22부터 n_estimator의 기본값을 10에서 100으로 변경했다. 100개의 트리가 분산을 줄이고 좋은 성능을 내는 데 충분할 수 있지만 데이터셋이 크면 500개 이상의 트리가 필요할 수 있다.
n_estimator=50으로 지정하고 OOB점수의 변화를 확인해보겠다.
1
2
3
rf = RandomForestClassifier(oob_score=True, n_estimators=50, random_state=2, n_jobs=-1)
rf.fit(X_census, y_census)
print(rf.oob_score_)
0.8518780135745216
확실히 성능이 향상되었다. 그렇다면 100개는 어떨까?
1
2
3
rf = RandomForestClassifier(oob_score=True, n_estimators=100, random_state=2, n_jobs=-1)
rf.fit(X_census, y_census)
print(rf.oob_score_)
0.8551334418476091
조금 향상되었다. n_estimator를 계속 증가시키면 OOB점수는 결국 일정한 수준을 유지할 것이다.
3.3 warm_start
warm_start 매개변수는 랜덤 포레스트의 트리 개수(n_estimators)를 결정하는데 도움이 된다. warm_start=True로 설정하면 처음부터 시작하지 않고 트리를 앙상블에 추가할 수 있다. n_estimators를 100에서 200으로바꾸면 200개의 트리를 가진 랜덤 포레스트를 만드는데 2배 더 오래걸린다. warm_start=True로 지정하면 처음부터 200개의 트리를 다시 만들지 않고 이전 모델에 이어서 트리를 추가한다.
warm_start 매개변수를 사용해 n_estimator에 따라 OOB 점수의 변화를 그래프로 그릴 수 있다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
import matplotlib.pyplot as plt
import seaborn as sns
sns.set()
oob_scores = []
rf = RandomForestClassifier(n_estimators=50, warm_start=True,
oob_score=True, n_jobs=-1,
random_state=2)
rf.fit(X_census, y_census)
oob_scores.append(rf.oob_score_)
est = 50
estimators = [est]
for i in range(9):
est += 50
estimators.append(est)
rf.set_params(n_estimators=est)
rf.fit(X_census, y_census)
oob_scores.append(rf.oob_score_)
plt.figure(figsize=(15, 7))
plt.plot(estimators, oob_scores)
plt.xlabel('Number of Trees')
plt.ylabel('oob_score_')
plt.title('Random Forest Warm Start', fontsize=15)
plt.show()
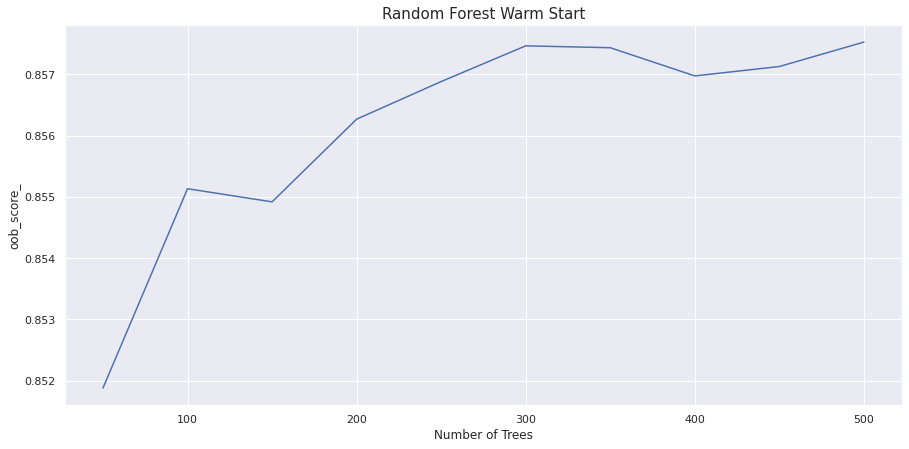
트리 개수 300개에서 점수가 가장 높다. 300개 이상의 트리를 사용하는 것은 비용과 시간 낭비이며 얻을 수 있는 이득이 크지 않다.
3.4 bootstrap
bootstrap=False로 설정하면 부트스트래핑을 사용하지 않는다. 따라서 oob_score_ 또한 사용할 수 없다.
과소적합이 일어나는 경우 적용해볼 수 있겠지만 쓸 일은 없을 듯 하다.
3.5 verbose
기본값은 0으로 높은 숫자를 주면 줄수록 출력이 많아진다. 한번 실험해보는 것을 추천
3.6 결정 트리 매개변수
트리 깊이
- max_depth
분할
- max_features
- min_samples_split
- min_impurity_decrease
리프 노드
- min_samples_leaf
- min_weight_fraction_leaf