
의역 99%, 지적 태클 환영
원문: Towards Deep Learning Models Resistant to Adversarial Attacks
0 초록
최근 연구들에서 심층 신경망이 adversarial example(원본 데이터와 거의 구별할 수 없지만 network가 오분류하는 입력)에 취약하다는 것과. adversarial attack의 존재가 딥러닝 모델의 내재적인 약점일 수 도 있다는 것이 밝혀졌다. 이를 해결하기 위해, robust optimization의 관점에서 신경망의 adversarial robustness를 살펴볼 것이다. 이러한 접근은 해당 주제의 이전 연구들보다 광범위하고 통일된 관점을 제공한다. 또한 이러한 원칙적인 성질은 신경망에 대한 훈련과 공격을 위한 신뢰할 수 있고, 어떤 의미에서는, 보편적인 방법을 제시할 수 있게 한다, 특히, 모든 적으로부터 보호할 수 있는 concrete security guarantee를 명시한다. 이러한 방법은 광범위한 적대적 공격에 크게 향상된 내성을 가진 network 훈련을 할 수 있게 하였다. 또한 자연스럽고 광범위한 security guarantee로써 first-order adversary에 대한 보안 개념을 제안한다. 우리는 이러한 adversaries의 잘 정의된 클래스가 완벽한 내성을 가진 딥러닝 모델로 향하는 디딤돌임을 믿는다.
1 개요
최근 컴퓨터 비전이나 자연어 처리에서의 획기적인 발전은 훈련된 분류기를 보안 중시 체계의 중심으로 끌어들이고 있다. 자율주행 자동차, 얼굴인식 그리고 멀웨어 감지는 대표적인 예시에 해당한다. 이러한 발전은 머신러닝의 보안적인 측면을 매우 중요하게 만들고 있다. 특히, 적대적으로 선택된 입력에 대한 저항이 중요한 설계 목표가 되고 있다. 잘 훈련된 모델은 일반적인 입력의 분류에 있어서 매우 효과적이지만, 최근 연구는 악의적으로 입력을 조작하여 모델이 잘못된 출력을 만들도록하는 것이 가능하다는 것을 보여준다.
이러한 현상은 심층신경망의 맥락에서 관심을 받았었고, 현재는 이 주제에 대한 연구가 급속도로 이루어 지고 있다. 컴퓨터 비전은 특히 주목할 만한 도전을 제공한다: 입력 이미지에 미세한 변경만을 주어도 SOA 신경망을 높은 신뢰도로 속일 수 있다. 이때 모델은 일반적인 입력은 제대로 분류하며, 변경된 차이에 대해서 인간은 인지할 수 없다. 보안적인 부분을 떼고 생각하더라도, 이러한 현상은 현재의 모델이 견고한 방식으로 기저 개념을 학습하는게 아니라는 것을 입증한다. 이러한 모든 발견은 하나의 근본적인 질문을 떠오르게 한다:
어떻게 하면 적대적 입력에 robust한 심층 신경망을 훈련할 수 있는가?
현재 적대적인 환경에서의 공격과 방어에 대한 다양한 메커니즘을 제시한 상당한 양의 연구가 존재한다. defensive distillation, feature squeezing 그리고 일부 다른 적대적 예제 감지에 대한 접근이 이에 포함된다. 이 연구들은 이곳의 가능성의 영역을 탐구하는 중요한 첫 발자국이 되었다. 그러나 그들은 그들이 제공한 보장에 대한 양질의 이해를 제공하지 않는다. 우리는 주어진 공격이 맥락안에서 “가장 적대적인” 예인지, 혹은 특정한 방어 메커니즘이 어떤 종류의 적대적 공격을 예방하는지 결코 확신할 수 없다. 이는 adversarial robustness를 조사하거나 가능한 보안에 대한 효과를 완전히 평가하는 것을 어렵게 한다.
본 문서에서는 robustness optimization의 관점에서 신경망의 adversarial roboustness를 조사할 것이다. 원칙적인 방식으로, 적대적 공격에 대한 보안의 개념을 잡기 위해 말 안장점(min-max) 공식을 사용한다. 이 공식은 달성하고자 하는 security guarantee의 유형, 즉 특정한 잘 알려진 공격만 방어하는 것과 달리, 광범위한 공격에 저항하는 것에 대해서 정확히 파악할 수 있게 해준다. 또한 공식화을 통해 공격과 방어를 모두 공통된 이론적 토대에 보낼 수 있으며, 적대적 예제에 대한 이전의 연구들의 대부분을 자연스럽게 캡슐화할 수 있게 한다. 특히, 적대적 훈련은 이 말안장점 문제를 최적화 하는 것에 직접적으로 연관되어 있다. 이와 유사하게, 신경망을 공격하는 이전의 방법들은 기저가 되는 제한된 최적화 문제를 푸는 특정한 알고리즘과 연관되어 있다.
이러한 관점에서 우리는 다음과 같은 성과를 냈다.
- 우리는 이 말안장점 식과 관련된 optimization landscape(최적화 공간의 모양)의 세심한 실험적인 연구를 시행한 후, non-convexity와 non-concavity에도 불구하고, 내제된 최적화 문제가 다루기 쉽다는 것을 발견하였다. 특히, 우리는 first-order method가 확실히 이 문제를 해결할 수 있다는 강력한 증거를 제시한다. projected gradient descent(PGD)를 보편적인 “first-order adversary”로써 강하게 제시하는 실해석학(real analysis)에서의 아이디어와 함께 이러한 통찰을 보충할 것이다. first-order adversary란, network에 대한 local first order 정보를 이용한 가장 강한 공격이다.
- network 구조가 adversarial robustness에 미치는 영향과 model capacity가 이것에 중요한 역할을 한다는 것을 알아냈다. 강한 adversarial attack에 안정적으로 견뎌내기 위해, newtork에게는 일반적인 입력만을 올바르게 분류하는 데 필요한 것보다 더 큰 capacity가 요구된다. 이는 말안장점 문제의 robust decision boundary가, 일반적인 입력을 분류하는 decision bondary에 비해서 상당히 복잡해 질 수 있다는 것을 보여준다.
- 위의 통찰을 바탕으로, 광범위한 적대적 공격에 robust한 MNIST와 CIFAR에서 network를 훈련시켰다. 우리의 접근은 앞서 언급한 말안장점 공식 최적화에 기반했으며, 신뢰할 수 있는 first-order adversary로 PGD를 사용하였다. 우리의 최고의 MNIST 모델은 테스트 군의 가장 강한 adversary들로부터 89% 이상의 정확도를 달성했다. 심지어 우리의 MNIST network는 iterative adversary의 white box attack 에서도 robust하였다. 같은 adversary에서 우리의 CIFAR10 모델은 46%의 정확도를 달성했다. 더욱이, 약한 black box/transfer 공격에서, 우리의 MNIST와 CIFAR10 network는 각각 95%이상, 64%이상의 정확도를 달성했다(더 자세한 개요는 [표1]과 [표2]에서 볼 수 있다). 우리가 아는 한, 이러한 광범위한 종류의 공격에서 이 정도 수준의 robustness를 달성한 것은 우리가 최초이다.
종합하자면, 이러한 발견들은 안전한 신경망이 도달 범위 안에 있음을 제시한다. 이 주장을 더욱 뒷받침 하기 위해, 우리는 challenge 형태로 우리의 MNIST와 CIFAR10 network을 공격하는 커뮤니티에 초대한다. 이것은 우리의 모델의 robustness를 정확하게 평가시켜줄 것이며, 그 과정에서 새로운 공격 방법으로 이어질 가능성이 있다. 도전 과제에 대한 설명과 전체 코드는 https://github.com/MadryLab/mnist_challenge 과 https://github.com/MadryLab/cifar10_challenge 에서 볼 수 있다.
2 적대적 Robustness에 대한 최적화 관점
우리의 논의의 대부분은 적대적 robustness를 주로 할 것이다. 이러한 관점은 우리가 연구하고자 하는 현상뿐만 아니라 연구 결과 또한 정확하게 포착할 수 있게 한다. 끝에서 기본이 되는 데이터 분포 $\mathcal{D}$의 $x\in\mathbb{R}^d$에 대응하는 $y\in[k]$ 예제 쌍에서의 표준 분류 작업을 고려할 것이다. 또한 신경망에서의 cross-entropy loss와 같은 적절한 손실 함수 $L(\theta, x, y)$가 주어졌다고 가정한다. 늘 그렇듯, $\theta \in \mathbb{R}^p$는 모델 파라미터의 집합이다. 이제 우리의 목표는 risk(=loss value) $\mathbb{E}_{(x, y)\sim \mathcal{D}}[L(x, y, \theta)]$를 최소화하는 모델 파라미터 $\theta$를 찾는 것이다.
Empirical risk minimization (ERM, 경험적 위험도 최소화)은 population risk가 작은 분류기를 찾는 것에 크게 성공적이었다. 불행하게도, ERM은 종종 적대적으로 생성된 예제들에 robust한 모델을 산출하지 않는다. 클래스 $c_1$에 속한 입력 $x$와, $x$와 매우 유사하지만 클래스를 $c_2\not=c_1$으로 분류하는 입력 $x^{adv}$를 찾는 효율적이고 공식적인 알고리즘(이하 ”adversaries”)이 존재한다.
적대적 공격에 신뢰적인 모델 훈련을 위하여, ERM 패러다임을 적절하게 보강하는 것이 필요하다. 우리는 특정한 공격에 대한 robustness를 직접적으로 향상시키는 방법들을 재정립하는 대신, adversarially model이 만족해야 하는 concrete guarantee를 최초로 제시한다. 그런 다음, 해당 guarantee를 달성하는 쪽으로 모델을 적응시킨다.
이러한 guarantee를 향한 첫 발걸음은, 모델이 저항해야 하는 공격의 정확한 정의인 attack model을 특정하는 것이다. 각 데이터 포인트 $x$에 대한 허용된 교란들의 집합$\mathcal{S}\subseteq \mathbb{R}^d$을 소개한다. $\mathcal{S}$는 adversary의 조작력(manuipulative power)를 공식화한다. 이미지 분류에서 $\mathcal{S}$를 선택하여 이미지들 사이의 지각적인 유사성(perceptual similarity)을 포착한다. 예를 들어, $x$를 중점으로 하는 $\ell_\infty$-ball이 적대적 교란에 대한 기본적인 개념으로 최근 연구되어 왔다. 우리는 본 논문에서 $\ell_\infty$-bounded 공격에 대한 robustness에 초점을 맞추지만, 지각적 유사성에 대한 보다 포괄적인 개념은 향후 연구의 중요한 방향이라는 것을 언급한다.
다음으로, 위의 adversary를 포함하도록 population risk $\mathbb{E}_\mathcal{D}[L]$에 대한 정의를 변경한다. 분포 $\mathcal{D}$에서 loss $L$로 샘플들을 직접 주는 대신, 먼저 adversary가 입력을 교란시키도록 한다. 이는 우리 연구의 중심 목적인 다음의 말안장점 문제를 떠오르게 한다.
\[\min_\theta \rho(\theta), \quad\text{where}\quad \rho(\theta)=\mathbb{E}_{(x,y)\sim\mathcal{D}} \big[ \max_{\delta\in\mathcal{S}}L(\theta, x+\delta, y)\big] \tag{2.1}\]이러한 유형의 식(그리고 유한한 샘플들에 대한 각각의 대응물)은 Wald[30]으로 거슬러 올라가는 robust optimization에서 유구한 역사를 가지고 있다. 위 식은 우리 연구의 맥락에서 특히 유용하다.
첫째로, 이 식은 adversarial robustness에 대한 이전의 연구들을 아우르는 통합된 관점을 제공한다. 우리 관점의 줄기는 말안장점 문제를 속에 있는 것을 최대화(inner maximization)하고 겉에 있는 것을 최소화(outer minimization)하는 것으로 부터 비롯된다. 이 둘 모두 우리 맥락에 대한 자연스러운 해석을 가지고 있다. 내부 최대화 문제는 주어진 데이터 포인트 $x$에 대해, 높은 손실을 갖는 적대적 버전을 찾는 것을 목표로 한다. 이는 정확히 주어진 신경망을 공격하는 문제이다. 반면, 외부 최소화 문제의 목적은 model parameter를 찾아서, 내부 공격 문제가 제공한 “적대적 손실”을 최소화 하는 것이다. 이는 정확히 적대적 훈련 기술을 사용해 robust한 분류기를 훈련하는 문제이다.
둘째로, 말안장점 문제는 이상적인 robust 분류기가 달성해야 하는 명확한 목적을 robustness의 수치적인 척도로 제시한다. 특히, parameters $\theta$가 (거의) 희미한 risk를 산출했을 때, 해당 모델은 우리의 attack model이 한 공격에 대해 완벽하게 robust한 것이다.
본 논문은 심층 신경망의 맥락에서 말안장점 문제의 구조를 연구한다. 이러한 연구는 광범위한 적대적 공격에 대한 높은 내성을 가진 모델을 생성하는 훈련 테크닉을 발견할 수 있게 한다. 우리의 성과에 들어가기 앞서, 적대적 예제에 대한 이전의 연구들을 간단히 리뷰하고, 이것이 어떻게 위 식에 맞춰지는 지 자세하게 설명한다.
2.1 공격과 방어에 대한 통합적인 관점
적대적 예제에 대한 이전의 연구들은 다음 두 주요한 질문에 집중된다.
- 어떻게 하면 강력한 적대적 예제(작은 교란만을 요구하면서 높은 신뢰도로 모델을 속일 수 있는)를 생성할 수 있는가?
- 어떻게 하면 적대적 예제가 없게끔, 최소한 적대적 예제를 쉽게 찾을 수 없게끔 모델을 훈련시킬 수 있는가?
말안장점 문제(2.1)에서 우리의 관점은 위 둘 문제 모두에서 해답을 주었다. 공격 측면에서, 이전의 연구는 FGSM[11]과 이것의 다양한 변형[18]과 같은 방법들을 제시했다. FGSM은 $\ell_\infty$-bounded adversary 공격이며 다음과 같이 적대적 예제를 계산한다.
\[x+\epsilon \ \text{sgn}(\nabla_xL(\theta,x, y)).\]이 공격을 말안장점 공식의 내부를 최대화하는 간단한 one-step 방식의 공격으로 해석할 것이다. 더 강력한 adversary는 multi-step 변형인데, 이는 근본적으로 다음과 같은 음의 손실 함수에서의 사영된 경사 하강(projected gradient descent, PGD)이다.
\[x^{t+1}=\mathrm{\Pi}_{x+\mathcal{S}}(x^t+\alpha \ \text{sgn}(\nabla_x L(\theta, x, y))).\]무작위 교란의 FGSM같은 다른 방법들[29]이 제시되어 왔다. 명확하게, 이러한 접근들은 모두 (2.1)의 내부 최대화 문제를 해결하려는 개별적인 시도로 볼 수 있다.
방어 측면에서, 훈련 데이터셋은 종종 FGSM으로 생성한 적대적 예제들에 의해 보강된다. 최대화 문제를 선형화하는 이러한 접근도 (2.1)로부터 얻어진다. 단순화된 robust optimization 문제를 해결하기 위해, 모든 훈련 예제들을 FGSM으로 교란된 예제들로 대체하였다. 여러 adversary들로부터 훈련하는 것 같은 더욱 정교한 방어 메커니즘이 내부 최대화 문제의 더 좋고 철저한 근사라고 볼 수 있다.
3 보편적인 Robust Network를 향하여
적대적 예제의 현재의 연구는 보통 특정한 방어 메커니즘이나, 혹은 그러한 방어에 대한 공격에 집중한다. 공식 (2.1)의 중요한 특징은 작은 적대적 loss가, 허용된 공격에 대해서 신경망을 속이지 못한다는 guarantee를 준다는 것이다. 정의에 의해, 우리의 공격 모델로부터 허용된 모든 교란에 대한 loss가 작기 때문에, 어떠한 적대적 교란도 가능하지 않다. 이런 이유로, 이제부터 (2.1)의 양질의 해를 얻는 것에 집중할 것이다.
불행하게, 말안장점 문제가 준 종합적인 gurarantee는 분명히 유용하지만, 합리적인 시간에 좋은 해를 찾을 수 있는지는 명확하지 않다. 말안장점 문제 (2.1)을 푸는 것은 non-covex한 외부 최소화 문제와 non-concave한 내부 최대화 문제를 둘 다 붙잡고 씨름하는 것을 포함한다. 우리의 주요 성과 중 하나는 실제로 말안장점 문제를 해결할 수 있다는 것을 입증한 것이다. 특히, 이제부터 우리는 non-concave한 내부 문제 구조의 실험적인 연구에 대해서 논의한다. 우리는 이 문제와 연관된 loss 공간의 모양이 놀랍게도 local maxima를 다루기 쉬운 구조임을 입증할 것이다. 또한 이런 구조는 “궁극적인” first-order adversary로써 PGD를 가리킨다. 섹션 4와 5에서, network가 충분히 크다면, 훈련된 network의 결과가 광범위한 공격에 실제로 robust하다는 것을 보인다.
3.1 적대적 예제의 Landscape
내부 문제가 주어진 network와 데이터 포인트에 대해서 적대적 예제를 찾는 것임을 상기하자 (우리의 공격 모델로). 이 문제는 highly nonconcave한 함수를 최대화할 것을 요구하므로, 다루기 어렵다고 생각할 수 있다. 실제로, 이것은 내부 최대화 문제를 선형화하는 데 의존한 이전 연구에 의해 도달한 결론이다[15, 26]. 위에서 지적한 바와 같이, 이러한 선형화 접근은 FGSM과 같이 잘 알려진 방식을 산출한다. FGSM adversaries에 대해 훈련하는 것은 일부 성공을 보였지만, 최근 연구는 이 one-step 접근법의 중요한 단점을 강조한다. 즉, 미세하게 더 정교한 adversary들이 여전히 높은 loss를 갖는 입력을 찾을 수 있다는 것이다.
더 자세하게 내부 문제를 이해하기 위해, 우리는 MNIST와 CIFAR10에서의 여러 모델의 local maxima 공간의 모양을 연구한다. large-scale constrained opimization의 표준 방법이기 때문에, 실험의 주요 도구는 PGD이다. loss 공간의 모양의 많은 부분을 탐색하기 위해, 각 검증 셋트의 데이터 포인트를 둘러싸는 $\ell_\infty$-ball 의 많은 지점에서 PGD를 재시작한다.
놀랍게도, 실험 후 적어도 first-order 방법들에서는 내부 문제가 다루기 쉽다는 것을 발견했다. $x_i+\mathcal{S}$안에 많은 local maxima를 갖는 적대적 입력이 넓고 띄엄띄엄하게 흩뿌려져 있었지만, 매우 일관된 loss 값을 갖는 경향이 있었다. 이는 loss(model parameter에 대한 함수로써)가 일반적으로 매우 유사한 값을 가진 많은 local maxima를 가지기 때문에 신경망 훈련이 가능하다는 전통적인 믿음을 반영한다.
실험은 아래와 같은 특별한 현상들을 발견했다.
- 우리는 $x+\mathcal{S}$안의 무작위로 선택된 시작점에서 projected $\ell_\infty$ gradient descent를 사용할 때 adversary에 의해 달성된 loss가 상당히 일관적으로 빠르게 증가하는 것을 발견했다. ([그림1] 참조)
 [그림1] MNIST와 CIFAR10 검증 데이터셋에서 적대적 예제를 생성하는 동안의 cross-entropy loss값. 이 그림들은 PGD가 20 step 동작할 동안 손실이 어떻게 증가하는 지 보여준다. 각각의 동작은 동일한 일반 입력을 둘러싸고 있는 $\ell_\infty$-ball안의 균등하게 무작위인 점에서 시작하였다(다른 예제에 대한 추가적인 그림은 [그림11]에 있다). 적대적 손실은 적은 수의 반복 이후에 수평을 이룬다. 최적화 궤적과 최종 loss 값이 CIFAR10에서 특히, 상당히 몰려있다. 더욱이, 적대적으로 훈련된 network의 최종 loss 값은 표준 훈련보다 훨씬 작다.
[그림1] MNIST와 CIFAR10 검증 데이터셋에서 적대적 예제를 생성하는 동안의 cross-entropy loss값. 이 그림들은 PGD가 20 step 동작할 동안 손실이 어떻게 증가하는 지 보여준다. 각각의 동작은 동일한 일반 입력을 둘러싸고 있는 $\ell_\infty$-ball안의 균등하게 무작위인 점에서 시작하였다(다른 예제에 대한 추가적인 그림은 [그림11]에 있다). 적대적 손실은 적은 수의 반복 이후에 수평을 이룬다. 최적화 궤적과 최종 loss 값이 CIFAR10에서 특히, 상당히 몰려있다. 더욱이, 적대적으로 훈련된 network의 최종 loss 값은 표준 훈련보다 훨씬 작다.
- maxima의 집중에 대해 더욱 조사하여, 많은 수의 무작위 재시작을 관찰하였고, 최종 반복의 loss 값이 극단적인 이상치 없이 잘 집중된 분포를 따른다는 것을 관찰하였다. ([그림2] 참조; $10^5$번의 재시작을 기반으로 이 집중을 확인하였다)
 [그림2] MNIST와 CIFAR10 검증 데이터셋에서 다섯개의 예들에 대한 cross-entropy loss에서 주어진 local maxima값들. 각 예들은 예제들을 둘러싼 $\ell_\infty$-ball안의 균일하게 무작위한 $10^5$개의 지점에서 PGD를 시작하였고, 손실이 평평해질 때까지 PGD를 반복하였다. 파란 히스토그램은 표준 network의 손실에 해당하는 반면, 빤간 히스토그램은 적대적으로 훈련된 network의 손실에 해당한다. 적대적으로 훈련된 network의 손실이 눈에 띄게 작고, 최종 손실값들이 이상치 없이 매우 집중적이다.
[그림2] MNIST와 CIFAR10 검증 데이터셋에서 다섯개의 예들에 대한 cross-entropy loss에서 주어진 local maxima값들. 각 예들은 예제들을 둘러싼 $\ell_\infty$-ball안의 균일하게 무작위한 $10^5$개의 지점에서 PGD를 시작하였고, 손실이 평평해질 때까지 PGD를 반복하였다. 파란 히스토그램은 표준 network의 손실에 해당하는 반면, 빤간 히스토그램은 적대적으로 훈련된 network의 손실에 해당한다. 적대적으로 훈련된 network의 손실이 눈에 띄게 작고, 최종 손실값들이 이상치 없이 매우 집중적이다.
- maxima가 눈에 띄게 분리되어 있다는 것을 보이기 위해 모든 쌍 사이의 $\ell_2$ 거리와 각도를 측정하였고, 거리들이 $\ell_\infty$-ball안의 두 개의 무작위 지점 사이의 예상된 거리와 유사하게 분포되었다는 것과, 수직에 가까운 각도를 가진다는 것을 관찰하였다. local maxima 사이의 선분에 따르면, loss는 convex하며, 끝점에서 최댓값을 이루고 중간에서 상수 인자에 의해 감소된다. 그럼에도 불구하고, 전체 선분에서 손실은 무작위 지점에서의 손실보다 상당히 높다.
- 마지막으로, 우리는 maxima의 분포가 최근 발전된 적대적 예제에 대한 부분 공간 관점이 공격의 풍부함[29]을 완전히 포착하지 못한다는 것을 시사한다는 것을 발견했다. 특히, 입력의 그레디언트와 함께 음의 내적을 사용한 적대적 교란과, 교란의 규모가 증가함에 따라 그레디언트 방향과의 전반적인 상관관계가 약화된다는을 관찰했다.
이러한 모든 증거들은 다음에 보게 될 것처럼 PGD가 first-order 접근법들 사이에서 “보편적인” adversary라는 것을 가리킨다.
3.2 First-Order Adversaries
우리의 실험은 PGD가 찾은 local maxima가 일반적으로 훈련된 network와 적대적으로 훈련된 network 에서 모두 비슷한 손실값을 가진다는 것을 보여준다. 이런 집중적인 현상은 PGD adversary에 대한 robustness가 모든 first-order adversary들에 대한 robustness를 산출한다는 문제에 대한 흥미로운 관점을 시사한다. adversary가 입력에 관한 손실 함수의 그레디언트만 사용하는 한, PGD보다 훨씬 더 나은 local maxima를 찾지 못할 것으로 간주된다. 이 가설에 대한 더욱 실험적인 근거를 섹션5에서 다룰것이다: 만약 PGD adversary들에 robust하도록 network를 훈련한다면, 이것은 광범위한 다른 공격에도 robust하다.
물론, PGD에 대한 우리의 연구는 훨씬 더 큰 함숫값을 갖는 어떤 고립된 maxima의 존재를 배제하지 않는다. 그러나, 우리의 실험은 그러한 더 큰 local maxima가 first-order method로는 찾기 힘들 것임을 시사한다. 많은 무작위 재시작의 시도에도, 크게 다른 손실값의 함숫값을 찾지 못하였다. adversary의 계산 능력을 attack model에 통합하는 것은 현대 암호학의 초석인 polynomially bounded adversary의 개념을 연상시켜야 한다. 거기서, 이 고전적인 attack model은 adversary에게 해결하는 데 다항 시간이 드는 문제들만 풀 수 있도록 허락한다. 여기서 우리는 머신러닝 맥락에 더 적합하도록 adversary의 능력에 optimization-based 관점을 채용하였다. 결국에는, 우리는 많은 최근 머신 러닝 문제들의 대한 계산복잡도의 철저한 이해를 아직 개발하지 못했다. 그러나, ML의 대부분의 optimization 문제는 first-order 방법으로 해결되며, SGD의 변형들은 특히 딥러닝 모델을 훈련시키는 가장 효과 적인 방법이다. 따라서 우리는 first-order정보에 의존하는 형식의 공격이, 어떤 의미에서는, 딥러닝의 현재 관행에 보편적이라고 믿는다.
이 두가지 아이디어를 종합하면, robustness가 보장된 머신 러닝 모델로 가는 길이 도표화 된다. 네트워크를 PGD adversary에 대해 robust하도록 훈련하면 현재의 모든 접근 방식을 포괄하는 광범위한 공격에 대해 robust해질 것이다.
실제로, 이러한 robustness는 black-box attacks의 맥락에서 더욱 강해지는 것을 보장한다. 블박 어택이란, adversary가 target network에 직접적인 접근이 불가능한 상태에서 하는 공격을 뜻한다. 대신, adversary는 (대략적인)모델의 아키텍쳐나 훈련 데이터셋과 같은 보다 적은 특정한 정보만을 가진다. 이러한 attack model을 “zero order” 공격의 예시로 볼 수 있다. “zero order” 공격이란, adversary가 분류기에 직접적인 접근이 불가능하며, gradient feedback이 없는 특정 예제에 대한 검증만이 가능한 공격을 말한다.
우리는 appendix의 섹션 B에서 transferability에 대해 논의한다. 우리는 network capacity를 늘리고 훈련하는 상대(표준적인 훈련 대신 FGSM or PGD 훈련)를 강화시키면 transfer attack에 대한 내성이 향상된다는 것을 관찰했다. 또한, 예상한 것처럼, 그러한 공격에 대한 우리의 최고의 모델의 내성은 (가장 강한)first order 공격보다 훨씬 더 큰 경향이 있다.
3.3 적대적 훈련의 Descent Directions
앞서한 논의는 내부 optimization problem이 PGD를 적용함으로써 성공적으로 해결될 수 있다는 것을 시사한다. adversarially robust network를 훈련하기 위해, 우리는 (2.1) 말안장점 공식의 외부 optimization 문제 또한 해결할 필요가 있다. 즉, 내부 최대화 문제의 “적대적 손실”을 최소화하는 model parameter를 찾는 것이다.
신경망 훈련의 맥락에서, 손실함수를 최소화 하는 대표적인 방법은 Stochastic Gradient Descent (SGD)이다. 외부 문제의 그레디언트인 $\nabla_\theta\rho(\theta)$를 계산하는 자연스러운 방법은 내부 문제의 최대치에서 손실함수의 그레디언트를 계산하는 것이다. 이는 적대적 교란으로 입력을 대체하고 교란된 입력에 대해 일반적인 훈련을 하는것에 해당된다. 이것이 말안장점 문제에 대한 유효한 descent direction인지는 명확하지 않다. 그러나, 연속이고 미분가능한 함수의 경우, Danskin 정리(opimization의 고전적인 정리)는 이것이 실제로 참이며, 내부 최대치에서의 그레디언트는 말안장점 문제에서의 올바른 descent direction임을 설명한다.
Danskin 정리의 정확한 가정은 우리의 문제에 해당하지 않지만 (ReLU와 max-pooling 유닛으로 인해, 함수는 불연속이고 미분 불가능하며, 내부 문제의 근사적인 최대치만 계산하고 있다). 우리의 실험은 문제를 최적화하기 위해 이러한 그레디언트를 여전히 사용할 수 있음을 알려준다. 적대적 예제에서 손실의 그레디언트를 사용하여 SGD를 적용하면 [그림5]에서 볼 수 있듯이 훈련 중 말안장점 문제의 손실을 지속적으로 줄일 수 있다. 이러한 관찰은 우리가 신뢰할 수 있게 말안장점 문제 (2.1)을 최적화할 수 있다는 것과, 따라서 robust 분류기를 훈련할 수 있다는 것을 시사한다. 우리는 Danskin 정리를 수식적으로 설명하고 우리의 문제에 어떻게 적용됬는지 Appendix. A에서 설명한다.
4 Network Capacity와 적대적 Robustness
성공적으로 (2.1) 방정식을 해결하는 것은 robust를 보증하고, 분류기를 정확하게 하는 것에 충분하지 않다. 해당 문제에 대한 value(적대적 예제에 대해서 달성한 최종 loss)가 작고, 따라서 분류기의 동작이 guarantee를 제공한다는 것을 입증할 필요가 있다. 특히, 매우 작은 loss 값의 달성은 적대적 입력에 robust한 완벽한 분류기에 해당한다.
가능한 교란들의 고정된 집합 $\mathcal{S}$에 대해, 이 문제의 값은 우리가 학습하는 분류기의 아키텍쳐에 완전히 종속적이다. 결과적으로, 모델의 아키텍처 capacity는 전체적인 성능의 영향을 주는 주요한 요인이다. 높은 수준에서 말하자면(추상적으로), robust한 방식으로 예제들을 분류하는 것은 강력한 분류기를 요구하는데, 이는 적대적 예제의 존재가 문제의 decision boundary를 보다 복잡하게 만들기 때문이다. ([그림3] 참조)
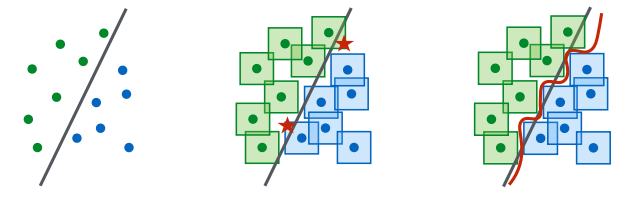 [그림3] 표준 decision boundary와 적대적 decision boundary의 개념도. 왼쪽은 간단한 decision boundary로 쉽게 분류 가능한 점들의 집합임. 가운데는 데이터 포인트를 둘러싸는 $\ell_\infty$-ball(사각형)을 분류하지 못하는 단순한 decision boundary. 따라서 적대적 예제들(빨간 별)이 오분류된다. 오른쪽은 $\ell_\infty$-ball을 분류하기 위한 더 복잡한 decision boundary임. 해당 분류기는 유계 $\ell_\infty$-norm 교란의 적대적 예제에 대해 robust하다.
[그림3] 표준 decision boundary와 적대적 decision boundary의 개념도. 왼쪽은 간단한 decision boundary로 쉽게 분류 가능한 점들의 집합임. 가운데는 데이터 포인트를 둘러싸는 $\ell_\infty$-ball(사각형)을 분류하지 못하는 단순한 decision boundary. 따라서 적대적 예제들(빨간 별)이 오분류된다. 오른쪽은 $\ell_\infty$-ball을 분류하기 위한 더 복잡한 decision boundary임. 해당 분류기는 유계 $\ell_\infty$-norm 교란의 적대적 예제에 대해 robust하다.
우리의 실험은 capacity가 강력한 adversary들에 대하여 성공적으로 훈련하는 것과, robustness에 중요하다는 것을 증명했다. MNIST 데이터셋에서, 우리는 간단한 합성곱 신경망을 고려하였고, 여러 adversary들로부터 network의 크기를 두 배씩 늘릴 때 어떻게 행동이 변화하는지 연구하였다. (합성곱 필터의 수와 fully connected layer의 크기를 두 배로 늘렸다.) network는 2개 필터의 합성곱 layer와, 이어서 4개의필터가 있는 또 다른 합성곱 레이어 그리고 64개의 유닛의 fully connected layer로 초기화되었다. 합성곱 레이어 뒤에는 $2\times 2$ max-pooling 레이어가 따르고 $\epsilon=0.3$의 적대적 예제로 구성되었다. 결과는 [그림4]에 있다.
CIFAR10 데이터셋에서는 ResNet 모델을 사용하였다. random crops와 flips를 이용하여 data augmentaion과 image standarization을 수행하였다. capacity를 늘리기 위해, network의 더 넓은 레이어를 포함하는 레이어를 10배로 수정하였다. 이는 각각 (16, 160, 320, 640)의 필터를 가진 5개의 residual unit의 network를 만들어냈다. 이 network는 일반적인 입력에서 훈련했을 때 95.2%의 정확도를 달성할 수 있었다. 적대적 예제는 $\epsilon=8.$로 만들어졌다. capacity 실험에 대한 결과는 [그림 4]에 있다.
 [그림4] network의 성능에서의 network capacity의 영향. 다양한 capacity에서 MNIST와 CIFAR10 network를 훈련하였다. (a)는 일반적인 입력이고, (b)는 FGSM이 만든 적대적 입력들, (c)는 PGD가 만든 적대적 입력이다. 각 데이터셋의 첫 세 개의 그림과 표에서, 표준과 적대적인 각각의 훈련 체제 하에서의 capacity에 따른 정확도의 변화를 보였다. 마지막 그림과 표에서는, network가 훈련된 적대적 입력들의 cross-entropy loss의 값을 보였다. 이는 허용된 교란들의 여러 집합들에 대한 말안장점 문제(2.1)의 값에 해당한다.
[그림4] network의 성능에서의 network capacity의 영향. 다양한 capacity에서 MNIST와 CIFAR10 network를 훈련하였다. (a)는 일반적인 입력이고, (b)는 FGSM이 만든 적대적 입력들, (c)는 PGD가 만든 적대적 입력이다. 각 데이터셋의 첫 세 개의 그림과 표에서, 표준과 적대적인 각각의 훈련 체제 하에서의 capacity에 따른 정확도의 변화를 보였다. 마지막 그림과 표에서는, network가 훈련된 적대적 입력들의 cross-entropy loss의 값을 보였다. 이는 허용된 교란들의 여러 집합들에 대한 말안장점 문제(2.1)의 값에 해당한다.
우리는 다음과 같은 현상들을 관찰했다:
capacity만으로도 도움이된다. 우리는 일반적인 예제들만으로 훈련할 때, network의 capacity를 늘리는 것이 one-step 교란의 robustness를 향상시키는 것을 관찰했다.
FGSM adversary들은 robustness를 향상시키지 않는다 (큰 $\epsilon$ 에 대해서). FGSM에서 생성된 적대적 입력들을 사용하여 network를 훈련할 때, network가 이러한 적대적 예제에 과적합되는 것을 발견했다. 이러한 행동은 label leaking[18]으로 알려져 있으며, adversary가 network가 과적합 할 수 있는 매우 제한적인 적대적 예제들의 집합을 생성한다는 사실에서 비롯된다. 이러한 network들은 일반적인 입력에서 좋지 않은 성능을 가지며, PGD adversary에 대한 어떤 종류의 robustness도 보이지 않았다. 더 작은 $\epsilon$의 경우, 일반적인 입력을 둘러싸고 있는 $\ell_\infty$-ball에서의 loss는 종종 충분히 선형적이어서, FGSM은 PGD에 의해 발견되는 것들과 유사한 적대적 예제를 발견하기 때문에, 훈련하기에 합리적adversary가 되는 것이다.
나약한 모델은 비자명한 분류기를 학습하는 데 실패할 수 있다. 작은 capacity의 network의 경우, 일반적인 훈련에서는 정확한 분류기가 될 수 있음에도 불구하고, 강력한 adversary (PGD)에 대한 훈련의 시도는 유의미한 것들의 학습을 막는다. 이 network는 항상 고정된 클래스를 예측하는 것에 수렴한다. network의 작은 capacity는 적대적인 입력에 대한 어떤 종류던지, robustness를 제공하기 위해 학습 과정에서 일반적인 입력에 대한 성능을 희생시키는 것을 강제한다.
말안장점 문제의 값은 capacity를 증가시킨 만큼 감소한다. adversary 모델을 고정시키고, 그것에 대해 훈련시킬 때, (2.1)의 값은 capacity가 증가한 만큼 감소했으며, 이는 모델이 적대적 예제에 더 적합될 수 있음을 의미한다.
큰 capacity와 강력한 adversary들은 transferability를 감소시킨다. network의 capacity를 증가시키거나, 내부 최적화 문제에 강력한 방법을 쓰는 것은 전이가능한 적대적 입력의 효율성을 감소시킨다. 우리는 source network와 transfer network의 그레디언트 간의 상관 관계가 capacity가 증가할 수록 덜 중요해지는 것을 관찰하여 이것을 실험적으로 검증했다. appendix B에서 이 실험에 대해 설명한다.
5 실험: 보편적으로 Robust한 딥러닝 모델
이전 섹션에서의 문제에 대한 이해에 따라, robust한 분류기를 훈련하는데 우리가 제안한 접근법을 적용시킬 수 있다. 우리의 실험들이 지금까지 입증했듯이, 두 가지 핵심 요소에 초점을 맞출 필요가 있다: a) 충분히 큰 capacity의 network를 훈련시키고, b) 가능한 가장 강력한 adversary를 사용한다.
MNIST와 CIFAR10 모두에서, 선택된 adversary는 일반적인 입력 주변의 무작위 교란에서 시작하는 PGD가 될 것이다. 이는 “완전한” first-order adversary에 대한 우리의 개념에 해당하며, 오직 first order 정보만을 사용하여 입력에 대한 loss를 효율적으로 최대화하는 알고리즘이다. 여러 에폭으로 모델을 훈련시키기 때문에, 배치마다 여러번 PGD를 재시작하는 것은 아무 이득도 없다. 즉, 각 입력을 마주칠 때마다 새로운 시작점이 선택될 것이다.
이러한 adversary에 대해서 훈련시킬 때, [그림 5]에서 나오듯이, 적대적 예제의 training loss에서의 꾸준한 감소를 관찰했다. 이러한 행동은 훈련시키는 동안 실제로 성공적으로 원래의 optimization 문제를 해결하고 있다는 것을 가리킨다.
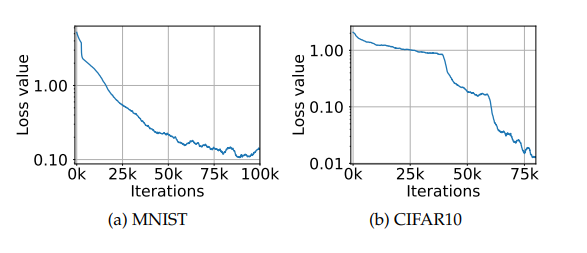 [그림5]: 훈련시키는 동안 적대적 예제에 대한 training loss. 이 그림들은 PGD adversary에 대한 MNIST와 CIFAR10 network의 훈련 예제에서의 adversarial loss가 어떻게 진행되는지 보여준다. CIFAR 10그림에서의 급격한 감소는 훈련 step 크기를 감소시킨것에 해당한다. 이 그림들은 지속적으로 말안장점 문제 (2.1)의 내부 문제의 값을 감소시키는 것을 보여주고, 따라서 robust 분류기를 향상적이게 생성하고 있다.
[그림5]: 훈련시키는 동안 적대적 예제에 대한 training loss. 이 그림들은 PGD adversary에 대한 MNIST와 CIFAR10 network의 훈련 예제에서의 adversarial loss가 어떻게 진행되는지 보여준다. CIFAR 10그림에서의 급격한 감소는 훈련 step 크기를 감소시킨것에 해당한다. 이 그림들은 지속적으로 말안장점 문제 (2.1)의 내부 문제의 값을 감소시키는 것을 보여주고, 따라서 robust 분류기를 향상적이게 생성하고 있다.
우리는 다양한 범위의 adversary에 대해서 훈련된 모델들을 평가했다. [표1]에서 MNIST에 대한 결과를 보이고, [표2]에서는 CIFAR10에서의 결과를 보인다. 우리가 고려한 adversary는 다음과 같다:
- source $A$로 표시되는 다양한 횟수의 반복과 재시작의 PGD white-box 공격.
- Carlini-Wagner(CW) loss 함수(정답과 오답의 logit의 차이를 직접적으로 optimizing함)[6]를 사용한 PGD white-box 공격. CW로 표시되며, 높은 신뢰도의 파라미터(k=50)의 해당되는 공격은 CW+로 표시된다.
- $A’$로 표시되는 독립적으로 훈련된 network의 사본에서의 Black-box 공격.
- $A_{nat}$로 표시되는 동일한 network의 일반적인 입력에서만 훈련된 버전에서의 black-box 공격.
- $B$로 표시되는 다양한 합성곱 아키텍처에서의 black-box 공격.
MNIST. 우리는 adversary로써 0.01의 step size로 40번 반복한 PGD을 사용하였다 ($\ell_\infty$ norm에서의 그레디언트 스텝을 취하기를 선택했다. 즉, step size를 간단히 만들어주기 때문에, 그레디언트의 부호를 더한 것이다). $\epsilon=0.3$크기의 교란에 대해서 훈련하고 검증하였다. 1024 크기의 fully connected 레이어와, 각각 $2\times 2$ max pooling과, 32개와 64개의 필터의 두 개의 합성곱 레이어로 구성된 network를 사용하였다. 일반적인 입력에서 훈련시킬 때, 이 network는 검증 셋에서 99.2%의 정확도를 달성하였다. 그러나 FGSM으로 교란된 입력에서 검증했을 때 정확도는 6.4%로 떨어졌다. 이 적대적 정확도 결과는 [표1]에서 보고된다. 주어진 MNIST 모델의 결과는 $\ell_\infty$-bounded adversary들에게 매우 robust하였고, 적대적 robustness에 영향을 미치는 지 이해하기 위해 학습된 파라미터를 조사하였다. 조사의 결과는 Appendix C에서 설명한다. 특히, 우리는 network의 첫번째 합성곱 레이어가 다른 가중치들은 sparse한 경향을 보이는 데 비해 입력 픽셀들의 threshold를 학습한다는 것을 발견하였다.
 [표1]: MNIST: 다양한 adversary에 대해서 $\epsilon=0.3$으로 적대적 훈련된 모델의 성능. 각 공격 모델에 대한 가장 성공적인 공격은 볼드체임. 공격을 위해 사용된 source network는 다음과 같다. 그 network 자체 (A) (white-box attack), 독립적으로 초기화되었으며, 이 훈련된 네트워크의 복사본 (A’), [29]의 아키텍처 (B).
[표1]: MNIST: 다양한 adversary에 대해서 $\epsilon=0.3$으로 적대적 훈련된 모델의 성능. 각 공격 모델에 대한 가장 성공적인 공격은 볼드체임. 공격을 위해 사용된 source network는 다음과 같다. 그 network 자체 (A) (white-box attack), 독립적으로 초기화되었으며, 이 훈련된 네트워크의 복사본 (A’), [29]의 아키텍처 (B).
CIFAR10. CIFAR10 데이터셋에서, 4에서 설명한 두 개의 아키텍쳐(original ResNet과 이것의 10x 변형)를 사용하였다. 다시 $\ell_\infty$ PGD adversary를 사용하여 network를 훈련시켰고, 이번에는 size 2의 7 스텝을 사용하였으며, 총 $\epsilon=0.8$ 이다. 다른 하이퍼파라미터의 선택이 정확도의 유의미한 감소를 일으키지 않았기 때문에, 가장 빡센 adversary로 같은 설정의 20스텝을 선택하였다. 실험의 결과는 [표2]에 나와있다.
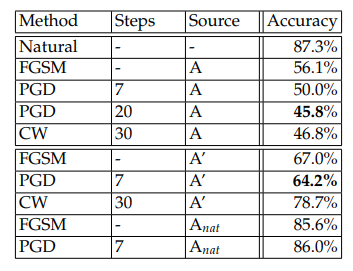 [표2]: CIFAR10: $\epsilon=8$의 다양한 adversary에 대해서 적대적으로 훈련된 모델들의 성능. 각 공격 모델에 대해서 가장 효과적인 공격은 볼드체로 표시하였다. 공격을 위해 고려된 source network는 다음과 같다: 이 network 자체 (A) (white-box attack), 독립적으로 초기화되고, 이 모델의 훈련된 복사본 (A’), 일반적인 입력에서 훈련된 network의 복사본 ($A_{nat}$)
[표2]: CIFAR10: $\epsilon=8$의 다양한 adversary에 대해서 적대적으로 훈련된 모델들의 성능. 각 공격 모델에 대해서 가장 효과적인 공격은 볼드체로 표시하였다. 공격을 위해 고려된 source network는 다음과 같다: 이 network 자체 (A) (white-box attack), 독립적으로 초기화되고, 이 모델의 훈련된 복사본 (A’), 일반적인 입력에서 훈련된 network의 복사본 ($A_{nat}$)
반복적인 adversary들의 힘을 고려할 때 network의 적대적 robustness는 상당한 수준이었지만 만족하기엔 부족했다. 이러한 방향으로 밀고 나가는 것과 더 큰 capacity의 network를 훈련시킴으로써 이러한 결과를 개선할 수 있다고 믿는다.
$\ell_2$ 와 $\epsilon$의 여러 값들에 따른 저항-bounded attacks. 모델의 적대적 robustness의 넓은 평가를 수행하기 위해, 두가지 추가적인 실험을 하였다. 하나는 여러값들의 $\epsilon$에 따른 $\ell_\infty$ bounded attack에 대한 내성을 조사하는 것이었고, 다른 하나는 $\ell_\infty$-norm과 반대로 $\ell_2$-norm에서의 bouned attack에 대한 저항을 시험하는 것이었다. $\ell_2$-bouned PGD의 경우, 부호가 아닌 그레디언트 방향으로 스텝을 취하고 스텝 사이즈 조정을 용이하게 하기 위해 스텝을 고정된 크기로 정규화했다. 모든 PGD 공격에서 $\epsilon$-ball안의 어떤 점에서 시작하던지 그것의 경계에 도달하는 것을 보장하기 위해 100스텝을 사용하였고, 스텝 사이즈를 $2.5\cdot \epsilon/100$으로 하였다. (경계에서의 움직임은 여전히 허용된다.) $\ell_\infty$-bounded attack에 대해 훈련된 모델은 MNIST에서 $\epsilon=0.3,$ CIFAR10에서 $\epsilon=8$을 사용했음을 상기하자. [그림6]에 이 결과가 나와있다.
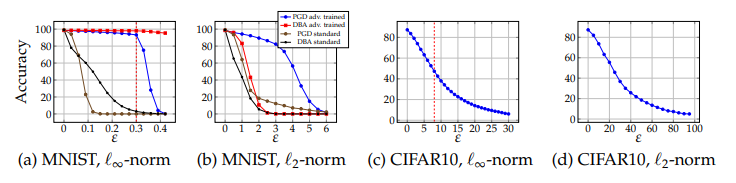 [그림6]: 다양한 강도의 PGD adversary들에 대해서 적대적으로 훈련 network의 성능. MNIST와 CIFAR10 network는 각각 $\epsilon=0.3$과 $\epsilon=8$의 PGD $\ell_\infty$ adversary에 대해서 훈련되었다. (이 훈련 $\epsilon$은 $\ell_\infty$플롯에서 빨간 점선으로 표현된다. MNIST에서 적대적으로 훈련된 network의 사례에서, 우리는 표준적인 2000스텝의 Decision Boundary Attack(DBA) [4]와 PGD, 그리고 각각에 대해서 적대적으로 훈련된 모델을 평가하였다. 우리는 훈련에 사용된 $\epsilon$의 값보다 작거나 같을 때, 성능이 크거나 같다는 것을 관찰하였다. MNIST에서는 짧은 진행 후 날카롭게 떨어졌다. 더욱이, MNIST에서 PGD를 사용한 $\ell_2$-trained network의 성능이 좋지않고, 모델의 robustness를 크게 과대평가하고 있다는 것을 관찰했다. 이는 모델이 학습한 threshold filter가 loss 그레디언트를 masking하는 것에 기인할 가능성이 있다. (decision-based attack은 그레디언트를 이용하지 않는다.)
[그림6]: 다양한 강도의 PGD adversary들에 대해서 적대적으로 훈련 network의 성능. MNIST와 CIFAR10 network는 각각 $\epsilon=0.3$과 $\epsilon=8$의 PGD $\ell_\infty$ adversary에 대해서 훈련되었다. (이 훈련 $\epsilon$은 $\ell_\infty$플롯에서 빨간 점선으로 표현된다. MNIST에서 적대적으로 훈련된 network의 사례에서, 우리는 표준적인 2000스텝의 Decision Boundary Attack(DBA) [4]와 PGD, 그리고 각각에 대해서 적대적으로 훈련된 모델을 평가하였다. 우리는 훈련에 사용된 $\epsilon$의 값보다 작거나 같을 때, 성능이 크거나 같다는 것을 관찰하였다. MNIST에서는 짧은 진행 후 날카롭게 떨어졌다. 더욱이, MNIST에서 PGD를 사용한 $\ell_2$-trained network의 성능이 좋지않고, 모델의 robustness를 크게 과대평가하고 있다는 것을 관찰했다. 이는 모델이 학습한 threshold filter가 loss 그레디언트를 masking하는 것에 기인할 가능성이 있다. (decision-based attack은 그레디언트를 이용하지 않는다.)
우리는 훈련하는 동안 사용한 것보다 더 작은 $\epsilon$의 경우, 예상과 같거나 더 높은 정확도를 달성하는 것을 관찰했다. MNIST에서, 학습된 threshold 연산자들이 훈련에 사용된 정확한 값의 $\epsilon$에 맞추어질 가능성 때문에, 미세하게 큰 $\epsilon$ 값들에서 robustness의 큰 하락이 있음을 알 수 있다. (Appendix C) 반면, CIFAR 10의 사례에서의 감쇠는 보다 부드러웠다.
MNIST에서의 $\ell_2$-bounded attack의 사례에서, PGD가 $\epsilon=4.5$와 같이 꽤 큰 $\epsilon$에도 불구하고, 적대적 예제를 찾지 못한다는 것을 발견했다. 이 $\epsilon$의 값을 관점적으로 보기 위해, Appendix D의 [그림12]에서 해당하는 적대적 예제의 샘플들을 제공한다. 우리는 이러한 교란들이 이미지의 ground-truth label을 바꾸는 데 충분히 유의미하다는 것을 관찰하였고, 우리의 모델이 실제로 그렇게 robust할 것 같지 않았다. 실제로, 하위 연구 [20, 25]는 PGD가 사실 이 모델의 $\ell_2$ robustness를 과대평가하고 있다는 것을 발견했다. 이러한 행동은 학습된 threshold filter(Appendix C)들이 그레디언트를 가리는 것과, PGD가 loss를 최대화하는 것에 대한 방해를 유발할 가능성이 있다. 모델의 그레디언트에 의존하지 않고 decision-based attack으로 모델을 공격하는 것은 모델이 $\ell_2$-bounded attack에 대해 보다 더 크게 취약하다는 것을 드러낸다. 그럼에도 불구하고, $\ell_\infty$ trained model은 여전히 일반적인 모델에 비해서 $\ell_2$공격에 대해 여전히 더 robust하다.
6 관련된 연구들
적대적 예제들에 대한 연구들이 많기 때문에, 가장 관련이 있는 논문들만 정리하였다. 우리의 기여와 비교하기 전에, robust optimization이 수십년동안 딥러닝의 주제 밖에서 연구되었음을 상기하자. 또한 적대적 ML 연구가 딥러닝의 광범위한 사용보다 앞선 것임에 주의하라.
(Ian J Goodfellow, Jonthan Shlens, and Christian Szegedy. Explaining and harnessing adversarial examples (ICLR), 2015) 에서 적대적 훈련이 도입되었지만, adversary의 활용은 흔하지 않았다. 즉, 데이터 포인트 주변의 loss를 선형화하는데 의존하였다. 결과적으로, 모델은 부분적인 adversary에 대해서는 robust하였지만 iterative 공격이 활용된 정교한 adversary들에게는 완전히 취약하였다.
또한 적대적 훈련에 대한 ImageNet에서의 최근의 연구(Alexey Kurakin, Ian J. Goodfellow, and Samy Bengio. Adversarial machine learning at scale (ICLR), 2017)는 model capacity가 적대적 훈련에 있어서 중요하다는 것을 밝혀냈다. 이 논문과 비교하면, 우리는 multi-step 방법 (PGD)으로 훈련하는 것이 이러한 adversary들에 대한 저항을 이끌어 낼 수 있다는 것을 밝혀냈다.
또한, (Ruitong Huang, Bing Xu, Dale Schuurmans, and Csaba Szepesvari. Learning with a strong adversary. arXiv preprint arXiv:1511.03034, 2015.)와 (Uri Shaham, Yutaro Yamada, and Sahand Negahban. Understanding adversarial training: Increasing local stability of supervised models through robust optimization. Neurocomputing, 307:195–204, 2018.)에서 min-max optimization 문제의 버전이 적대적 훈련에서 고려되었다. 그러나, 앞서 이 논문들에서 언급된 결과와 본 논문 사이에는 세가지 중요한 차이점이 존재한다. 첫째, 저자들은 inner maximization problem이 해결하기 어렵다고 주장한 반면, 우리는 더욱 자세하게 loss surface를 조사하였고 randomly re-started projected gradien descent가 대조적인 퀄리티로 종종 솔루션에 수렴한다는 것을 발견하였다. 이는 inner maximiztion problem에서 충분히 좋은 솔루션을 얻는 것이 가능하다는 것을 보여주었으며, 심층 신경망이 적대적 예제에 대한 내성을 가질 수 있다는 증거로 제시된다. 둘째, 이들은 one-step adversary만을 고려하였지만, 우리는 multi-step method를 사용하여 연구하였다. 추가적으로, Uri Shaham 외 연구진들의 논문에서의 실험은 유망한 결과를 만들어냈지만 오직 FGSM에 대해서만 검증하였다. 그러나, FGSM만을 이용한 검증은 완전히 신뢰할 수 없다. 익서에 대한 증거 중 하나로는 Uri Saham외 연구진들의 분류기는 $\epsilon=0.7$일 때 70%의 정확도를 산출하였지만, 각 픽셀을 $0.5$이상 교란할 수 있는 상대라면 균일하게 회색 이미지를 만들 수 있고, 따라서 이 분류기를 속일수 있다는 것이다.
또한 (Florian Tramer, Nicolas Papernot, Ian Goodfellow, and Patrick McDaniel Dan Boneh. The space of transferable adversarial examples. In ArXiv preprint arXiv:1704.03453, 2017.)와 같은 더욱 최근의 연구에서는 transferability 현상을 조사하였다. 이 연구는 손실이 선형(에 가까운) 자연적인 예제들의 주변 지역에 집중되어 진행되었다. 큰 교란이 있을 때, 이 지역은 adversarial landscape의 완전한 picture를 주지 않는다. 이것은 우리의 실험에 의해 확인될 뿐만 아니라 Florian Tramer외 연구진들에 의해서도 지적되었다.
7 결론
우리의 발견은 심층신경망이 적대적 공격에 내성을 가질 수 있다는 증거를 제시한다. 우리의 이론과 실험이 가리키듯이, 우리는 신뢰할 수 있는 적대적 훈련 방법을 설계할 수 있다. 이것의 뒤에 있는 중요한 통찰중 하나는, 기본적인 최적화의 예상 외의 규칙적인 구조였다. 관련된 문제는 많은 뚜렷한 국소 최댓값을 갖는 고도로 non-concave 함수의 최대화에 해당하지만, 그 값들은 매우 집중되어 있다. 종합하자면, 우리의 발견은 adversarially robust한 딥러닝 모델이 현재 도달 범위 내에 있을 수 있다는 희망을 준다.
MNIST 데이터셋에서, 우리의 network는 매우 robust하였고, 광범위하고 강력한 $l_\infty$ bound adversaries와 큰 perturbation에 대해서 높은 정확도를 달성했다. CIFAR10 데이터셋에서의 실험은 아직 이러한 수준까지 도달하지 못하였다. 그러나, 우리의 결과는 우리의 기술이 network의 robustness의 중요한 향상을 이끌어 낸다는 것을 이미 보여주었다. 우리는 이러한 방향의 더 많은 탐구가 이 데이터셋의 adversarially robust network를 이끌어 낼 수 있으리라고 믿는다.