
그레디언트 부스팅의 작동 방식을 살펴보고 이전 트리의 오차에 새로운 트리를 훈련하는 식으로 그레디언트 부스팅 모델을 만들어본다. 여기서 수학적인 핵심 요소는 잔차(residual)이다. 그 다음 사이킷-런의 그레디언트 부스팅 모델을 사용해 동일한 결과를 구해볼 것이다.
2.1 잔차 (Residual)
잔차는 타깃과 모델의 예측 사이의 차이이다. 통계에서는 일반적으로 선형 회귀 모델이 데이터에 얼마나 잘맞는지 평가하기 위해 잔차를 사용한다.
다음과 같은 예를 생각하자.
- 자전거 대여
- 예측: 759
- 타깃: 799
- 잔차: 799 - 759 = 40
- 소득
- 예측: 100,000
- 타깃: 88,000
- 잔차: 88,000 - 100,000 = -12,000
여기서 보듯이 잔차는 모델 예측이 정답에서 얼마나 떨어져 있는지 알려주며 양수 또는 음수일 수 있다.
다음은 선형 회귀 모델의 잔차를 알려주는 그림이다.
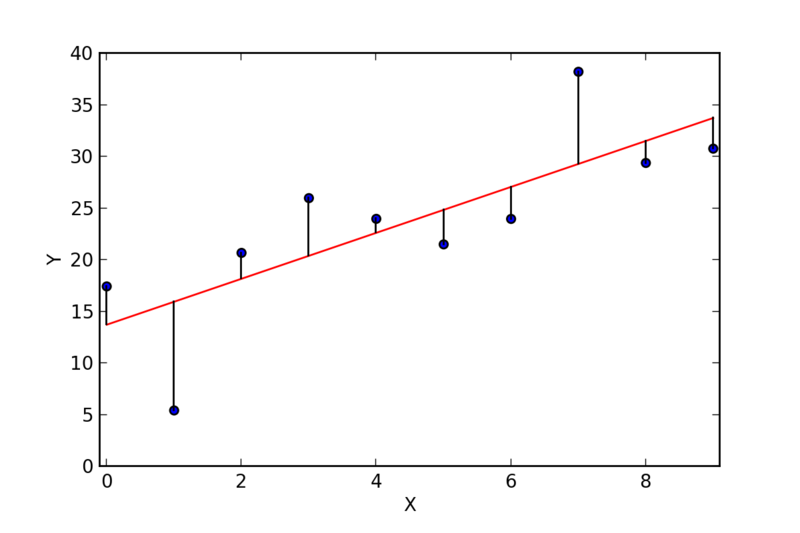
선형 회귀의 목적은 잔차의 제곱을 최소화하는 것이다. 그림에 나와 있듯이 잔차는 선형 회귀 직선이 데이터에 얼마나 잘 맞는지 보여준다. 통계학에서 종종 데이터에 대한 통찰을 얻기 위해 잔차를 그래프로 시각화하여 선형 회귀 분석을 수행한다.
그레디언트 부스팅 알고리즘을 직접 구현해보기 위해 각 트리의 잔차를 계산하고 이 잔차에 새로운 모델을 훈련해보자.
2.2 그레디언트 부스팅 모델 구현
모델을 직접 구현해보면 작동방식을 잘 이해할 수 있을 것이다. 모델을 만들기 전에 데이터를 준비하고 모델에 주입할 수 있도록 전처리 해준다.
자전거 대여 데이터셋 로드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
import xgboost as xgb
xgb.set_config(verbosity=0) # 로그 제거
df_bikes = pd.read_csv('./bike_rentals_cleaned.csv')
X_bikes = df_bikes.iloc[:, :-1]
y_bikes = df_bikes.iloc[:, -1]
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X_bikes, y_bikes,
random_state=2)
그레디언트 부스팅 모델 구현
1. 결정 트리 훈련
max_depth=1인 결정트리 스텀프를 사용하거나 max_depth=2 or 3인 결정트리를 사용할 수 있다. 기본학습기라 부르는 결정트리는 높은 정확도를 위해 튜닝하지 않는다. 기본 학습기에 크게 의존하는 모델이 아니라 오차에서 학습하는 모델을 원하기 때문이다. 앙상블의 첫번째인 tree_1을 max_depth=2로 결정트리를 초기화하고 훈련 세트에서 훈련한다.
1
2
3
4
5
6
7
8
9
10
11
12
from sklearn.tree import DecisionTreeRegressor
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
tree_1 = DecisionTreeRegressor(max_depth=2, random_state=2)
tree_1.fit(X_train, y_train)
# 기본학습기 플로팅
plt.figure(figsize=(13, 8))
plot_tree(tree_1, feature_names=list(X_train.columns),
filled=True, rounded=True, fontsize=10)
plt.show()
2. 훈련 세트에 대한 예측
테스트 세트가 아니라 훈련 세트에 대한 예측을 만든다. 잔차를 계산하기 위해서 훈련 단계에서 예측과 타깃을 비교해야 하기 때문이다. 모델의 테스트 단계는 모든 트리를 구성한 후 마지막에 온다. tree_1의 predict() 메소드에 X_train을 입력하여 첫 번째 반복에 대한 훈련 세트 예측을 만든다.
1
y_train_pred = tree_1.predict(X_train)
3. 잔차 계산
예측과 타깃사이의 차이를 구한다.
1
2
# 잔차는 다음 트리의 타깃이 되기 때문에 y2_train이라고 명명함
y2_train = y_train - y_train_pred
4. 새로운 트리 훈련
새로운 트리는 이 잔차를 맞추는 것을 목적으로 훈련한다. 잔차에서 트리를 훈련하는 것은 훈련 세트에서 훈련하는 것과 다르다. 주요한 차이는 예측값이다. 자전거 대여 데이터셋에서 잔차에 새로운 트리를 훈련할 때 점점 더 작은 값을 얻을 것이다. 새로운 트리를 초기화하고 X_train과 잔차인 y2_train에서 훈련한다.
1
2
tree_2 = DecisionTreeRegressor(max_depth=2, random_state=2)
tree_2.fit(X_train, y2_train)
5. 2~4 단계 반복
이 과정이 지속되면 잔차는 양수나 음수 방향으로 0에 가까워 진다. 양상블에 추가할 트리 개수 만큼 반복이 계속된다. 세번째 트리에서 이 과정을 반복해 볼 것이다.
1
2
3
4
y2_train_pred = tree_2.predict(X_train)
y3_train = y2_train - y2_train_pred
tree_3 = DecisionTreeRegressor(max_depth=2, random_state=2)
tree_3.fit(X_train, y3_train)
이 과정이 수십, 수백, 수천개의 트리까지 계속될 수 있다. 일반적인 상황이라면 계속 진행할 것이다. 약한 학습기를 강력한 학습기로 만드려면 몇 개 트리로는 부족하다. 여기서 목적은 그레디언트 부스팅의 작동방식을 이해하는 것이기 때무에 일반적인 개념을 다룬 것에 만족하고 다음으로 넘어가자.
6. 결과 더하기
다음 처럼 최종 결과를 위해 테스트 세트에 대한 각 예측을 만든다.
1
2
3
y1_pred = tree_1.predict(X_test)
y2_pred = tree_2.predict(X_test)
y3_pred = tree_3.predict(X_test)
각 예측의 잔차는 양수와 음수가 뒤섞여 있기 때문에 이 예측을 모두 더하면 타깃에 가까운 결과를 만들어 낼 수 있다.
\[R_i = R_{i+1}+y_{i+1}, \quad where \quad R_0=y_{true}\]7. 평가
마지막으로 다음처럼 평균 제곱근 오차 (MSE)를 계산한다.
1
2
from sklearn.metrics import mean_squared_error as MSE
MSE(y_test, y_pred)**.5
911.0479538776444
강력하지 않은 약한 학습기를 사용한 것 치곤 나쁘지 않다. 이제 사이킷-런을 사용해 동일한 결과를 만들어보자.
2.3 사이킷런의 그레디언트 부스팅 모델
사이킷런의 GradientBoostingRegressor를 사용해 이전과 동일한 결과를 얻을 수 있는 지 확인해보자. 이를 위해 몇 개의 매개변수를 조정할 것이다. GradientBoostingRegressor를 사용하면 그레디언트 부스팅 알고리즘을 훨씬 쉽고 빠르게 구현할 수 있다.
1
2
3
4
5
6
7
8
from sklearn.ensemble import GradientBoostingRegressor
gbr = GradientBoostingRegressor(max_depth=2, n_estimators=3,
random_state=2, learning_rate=1.0)
gbr.fit(X_train, y_train)
y_pred = gbr.predict(X_test)
MSE(y_test, y_pred)**.5
911.0479538776439
이 결과는 소수점 11자리까지 모두 같다! 이제 반복횟수를 점점 늘려볼 것이다.
1
2
3
4
5
6
gbr = GradientBoostingRegressor(max_depth=2, n_estimators=30,
random_state=2, learning_rate=1.0)
gbr.fit(X_train, y_train)
y_pred = gbr.predict(X_test)
MSE(y_test, y_pred)**.5
857.1072323426944
점수가 향상되었다. 이번에는 300개로 늘려보자.
1
2
3
4
5
6
gbr = GradientBoostingRegressor(max_depth=2, n_estimators=300,
random_state=2, learning_rate=1.0)
gbr.fit(X_train, y_train)
y_pred = gbr.predict(X_test)
print(MSE(y_test, y_pred)**.5)
936.3617413678853
오잉? 점수가 나빠졌다. learning_rate을 제거하고 기본값을 사용해보자.
1
2
3
4
5
6
gbr = GradientBoostingRegressor(max_depth=2, n_estimators=300,
random_state=2)
gbr.fit(X_train, y_train)
y_pred = gbr.predict(X_test)
print(MSE(y_test, y_pred)**.5)
653.7456840231495
오… 사이킷-런의 learning_rate기본값을 사용해 점수를 936에서 654로 낮추었다.
다음에는 learning_rate 매개변수에 초점을 맞추면서 그레디언트 부스팅의 다른 매개변수에 대해 알아보도록 하자.