
의역 99%, 지적 태클 환영
원문: Explaining and harnessing adversarial example
초록
신경망을 포함한 일부 머신러닝 모델들은 적대적 예제들을 일관적으로 오분류한다. 적대적 예제란, 데이터셋에서 미세하지만 의도적으로 worst-case 방향으로 교란(perturbation, 이하 교란)을 주어서 만든 입력값를 말한다. 이렇게 함으로써 모델은 높은 신뢰도(confidence, 동일한 측정대상을 측정하였을 때 일관성 있는 측정 결과를 산출하는 정도)로 잘못된 답을 내놓게 된다. 이러한 취약점은 원래 비선형성과 과적합에 집중되어 설명되고 있었는데, 우리는 이와 다르게 선형성에 있다고 주장할 것이다. 이는 새로운 수치적인 근거로 뒷받침되며, 최초로 모델의 아키텍처와 훈련 데이터셋을 아우르는 일반화(generalization)에 대한 흥미로운 설명을 제시할 것이다. 또한 이러한 관점에서 적대적 예제를 생성하는 간단하고 빠른 방법을 제시할 것이다. 이러한 방법을 이용한 예제들을 적대적 훈련에 이용한 결과, MNIST 데이터셋에서의 maxout network의 테스트셋에서의 에러를 줄일 수 있었다.
개요
Szegedy et al,. (2014b)는 SOA(State-Of-Art, 현존 최고 성능) 신경망을 포함한 일부 머신 러닝 모델들이 적대적 예제에 취약하다는 점을 발견했다. 즉 이러한 머신 러닝 모델들은 올바르게 분류된 예시에 미세한 변경만을 가해도 이것을 잘못 분류한다는 것이다. 서로 다른 아키텍쳐를 가진 다양한 모델 대부분이 동일한 적대적 예제를 오분류했다. 이는 적대적 예제가 현존 훈련 알고리즘이 근본적인 맹점(blind spot)을 가지고 있다는 것을 알려준다고 볼 수 있다.
지금까지 위 현상의 원인은 미스테리였다. 신경망의 과도한 비선형성이 원인으로 제시 되었으며, 순수한 지도 학습 문제의 불충분한 model averaging과 불충분한 정규화, 그리고 신경망의 과도한 비선형성이 원인으로 추측되고 있었다. 우리는 이러한 가설이 필요없다는 것을 보여줄 것이다. 고차원 공간에서의 선형 행동은 위 현상의 원인이 되기에 충분하다. 이 관점을 통해 적대적 훈련을 실용화 할 수 있도록 적대적 사례를 생성하는 빠른 방법을 설계할 수 있다. 우리는 적대적 훈련이 드롭아웃(Srivastava et al., 2014)을 단독으로 사용함으로써 제공되는 것보다 더 많은 정규화 이점을 제공할 수 있음을 보여준다. 드롭아웃, 사전학습, model averaging과 같은 일반적인 정규화 전략들은 적대적 사례에 대한 모델의 취약점을 크게 없애주지 않는다. 그러나 RBF network와 같은 비선형 모델류로 바꾸는 것은 그렇게 할 수 있다.
우리의 설명은 선형성으로 인한 모델 훈련의 용이성과 비선형성으로 인한 적대적 예제에 대한 모델의 내성 사이의 근본적인 균형을 제안한다. 장기적으로 더 많은 비선형 모델을 성공적으로 훈련시킬 수 있는 더 강력한 최적화 방법을 설계함으로써 이러한 trade-off를 피하는 것이 가능하다고 보고 있다.
2 관련된 연구
Szegedy et al,. (2014b)는 신경망과 관련된 모델들의 다양하고 놀라운 특징을 발견했다. 아래는 본문과 가장 연관된 연구들이다.
- Box-constrained L-BFGS can reliably find adversarial examples.
- On some datasets, such as ImageNet (Deng et al., 2009), the adversarial examples were so close to the original examples that the differences were indistinguishable to the human eye.
- The same adversarial example is often misclassified by a variety of classifiers with different architectures or trained on different subsets of the training data.
- Shallow softmax regression models are also vulnerable to adversarial examples.
- Training on adversarial examples can regularize the model—however, this was not practical at the time due to the need for expensive constrained optimization in the inner loop.
이러한 결과는 현대 기계 학습 기술을 기반으로 한 분류기가 테스트 세트에서 우수한 성능을 얻는 분류기일지라도 올바른 출력 레이블을 결정하는 진정한 기본 개념을 학습하지 못하고 있음을 시사한다. 이들 알고리즘은 자연적으로 발생하는 데이터에는 잘 작동하지만, 데이터 분포에서 거의 발생하지 않는 입력을 주면 가짜인 것이 들통나는 포템킨 마을을 구축했다. 이것은 조금 실망스러운데, 왜냐하면 computer vision에서 인기있는 접근은 합성곱 신경망 feature를 지각 거리에서 유클리드 거리로 근사하는 공간으로 사용하는것이기 때문이다. 측정할 수 없을 정도로 작은 지각 거리를 가진 이미지가 네트워크 표현에서 완전히 다른 클래스에 해당한다면 이러한 유사성은 분명히 결함이 있다고 볼 수 있다.
위 결과는 선형 분류기가 동일한 문제를 가지고 있음에도 특히 심층 신경망의 단점으로 해석되어왔다. 우리는 이러한 결함을 그것을 해결하여 모델의 성능을 향상 시킬 기회로 여기고 있다. 실제로 클-린한 입력에 대해 최신 정확도를 유지하면서 성공적으로 수행된 모델은 아직 없지만, Gu & Rigazio(2014)와 Chalupka 등(2014)은 적대적 교란에 저항하는 모델을 설계하기 위한 첫 단계를 이미 시작했다.
적대적 예제와 선형성에 대한 설명
선형 모델에서의 적대적 예제의 존재부터 설명하겠다.
많은 문제에서, 개별 입력 feature의 정밀도는 유한하다. 에를 들어 디지털 이미지는 픽셀 당 8비트을 사용하기 때문에, 1/255이하 크기인 모든 정보를 버린다. 이와 같이 feature들의 정밀도는 유한하며, 교란된 입력과 원래 입력의 차이가 정밀도 이하라면, 분류기가 입력 $x$와 교란된 적대적 예제 $\tilde{x}=x+\eta$를 다른 클래스로 분류하는것은 타당하지 않다. 수식적으로, 균일하게 분포된 클래스를 분류하는 문제에서 $||\eta||_\infty<\epsilon$ 일 때, 분류기는 $x$와 $\tilde{x}$를 같은 클래스로 분류할 것으로 기대된다. 이 때 $\epsilon$은 저장 장치나 센서에게 무시될 수 있을 정도로 충분히 작은 값이다.
이제 가중치 벡터 $w$와 적대적 예제 $\tilde{x}$ 사이의 내적을 고려하자.
\[w\cdot \tilde{x}=w\cdot x+w\cdot \eta\]적대적 교란은 활성화 값을 $w\cdot \eta$ 만큼 증가 시킨다.
$\eta=sign(w)$로 설정함으로써 $\eta$에 max norm constraint($sign((1, -2, 3))=(1, -1, 1),$ 이와 같이 벡터의 각 원소의 크기가 1로 변경 되어 최종 norm 크기가 제한된다)을 가하여, 이 증가를 최대화 할 수 있다. $w$ 가 $n$ 차원이고 가중치 벡터의 각 요소의 평균 크기가 $m$ 일 때, 활성화 값은 $mn$만큼 증가한다. $||\eta||_\infty$ 는 문제의 차원에 따라 증가하지 않지만, $\eta$ 에 의한 교란으로 인한 활성화 값은 $n$ 에 따라 증가 할 수 있고, 고차원 문제라면 입력값에 수많은 무한소 변경을 가하여 출력값에 큰 변화를 줄 수 있다. 선형 모델은 여러 신호가 존재하고, 다른 신호들이 다른 신호들이 더욱 큰 진폭을 가졌더라도, 모든 가중치들에 가장 가까운 신호쪽으로 정렬되도록 강제된다. 이것을 “우발적 스테가노그래피 (accidental steganography)”라고 생각할 수 있다.
위 설명은 단순 선형 모델에서 입력값이 고차원일 경우 적대적 예제를 가질 수 있음을 보여준다. 적대적 예제에 대한 기존의 설명들은 신경망의 고도의 비선형성등 과 같은 가정된 특징을 사용하였다. 그러나 선형성에 기반한 가설은 이보다 더 간단하며, softmax regression 이 왜 적대적 예제에 취약한지에 대해서도 설명할 수 있다.
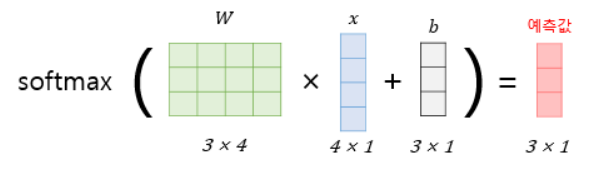 Softmax regression, $x$가 $768 \times 1$ 이라면 교란됬을 때 출력의 변경이 유의미해질 수 있다.
Softmax regression, $x$가 $768 \times 1$ 이라면 교란됬을 때 출력의 변경이 유의미해질 수 있다.
4 비선형 모델들의 선형 교란
적대적 예제가 선형성 때문이라는 관점은 이것을 빠르게 생성하는 방법을 제공한다. 우리는 신경망이 적대적 예제에 저항하기에는 너무 선형적이라는 가설을 세웠다. LSTM, ReLUs, 그리고 maxout network는 모두 최적화하기에 용이하도록, 의도적에게 선형적으로 설계되었다. sigmoid network와 같은 모델들은 위와 같은 이유로 그들의 시간을 거의 non-saturating하거나 선형화하는데 쓰도록 세심히 튜닝되었다. 이러한 선형성은 모델을 쉽고, 분석적인 교란으로 손상 시킬 수 있게한다.
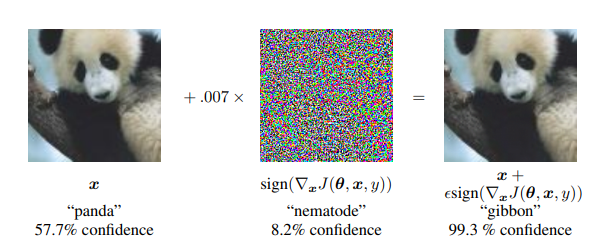 [그림1] 빠른 적대적 예제 생성이 ImageNet의 GoogLeNet에 적용된 모습이다. 무시할 수 있을 만큼 작은 벡터를 cost function의 기울기와 부호를 동일하게 하여 더함으로써, GoogLeNet의 이미지 분류 결과를 바꿀 수 있다. 이 떄 GoogLeNet의 실수 변환 후 8비트 이미지 인코딩에서 가장 작은 비트의 크기(정밀도)는 $\epsilon=0.007$일 때이다.
[그림1] 빠른 적대적 예제 생성이 ImageNet의 GoogLeNet에 적용된 모습이다. 무시할 수 있을 만큼 작은 벡터를 cost function의 기울기와 부호를 동일하게 하여 더함으로써, GoogLeNet의 이미지 분류 결과를 바꿀 수 있다. 이 떄 GoogLeNet의 실수 변환 후 8비트 이미지 인코딩에서 가장 작은 비트의 크기(정밀도)는 $\epsilon=0.007$일 때이다.
모델의 파라미터를 $\theta,$ 입력을 $x$, $x$에 따른 정답 레이블을 $y$라고 하고 신경망의 훈련에 사용하는 cost function을 $J(\theta, x, y)$라고 하자. $\theta$의 현재 값을 기준으로 비용함수를 선형화 할 수 있을 것이다. 또한 이때 다음과 같은 최적의 max-norm-contraint된 교란값 $\eta$을 얻을 수 있다.
\[\eta=\epsilon sign(\nabla_xJ(\theta, x, y))\]이것을 적대적 예제 생성의 “빠른 그레디언트 부호 방법(fast gradient($:=\nabla_x$) sign($:= sign()$) method, FGSM)”이라고 칭한다. 이때 역전파를 사용하여 효율적으로 그레디언트를 계산할 수 있다.
우리는 이 방법이 다양한 모델들의 오분류를 유발한다는 것을 확실하게 발견했다. [그림1]의 ImageNet에서의 시연을 참고하자. 이때 사용한 $\epsilon=0.25$이다. 또한 우리는 MNIST 데이터셋에서 shallow softmax classifier가 79.3%의 신뢰도로 99.9%의 에러율을 내도록 유발하였다. 같은 세팅에서 maxout network는 우리의 적대적 예제들을 평균 신뢰도 97.6%로 89.4% 잘못 분류 하였다. 비슷하게, 마찬가지로, $\epsilon=0.1$일 때, CIFAR-10 테스트 셋의 전처리된 버전에서 convolutional maxout network를 사용하였을 때 87.15%의 에러율과 잘못된 레이블에 할당될 평균 확률 96.6%를 얻었다. 적대적 예제를 생성하는 다른 쉬운 방법도 가능하다. 예를 들어, 입력 $x$를 그레디언트$(\nabla_x J)$방향으로 작은 각도로 회전시키면 확실하게 or 안정적으로 (reliably) 적대적 예제를 생성할 수 있다.
이러한 간단하고 저비용의 알고리즘이 오분류를 유발하는 적대적 예제를 생성할 수 있다는 것은 적대적 예제를 선형성의 결과로 해석하는 근거로 유리하게 작용한다. 이 알고리즘은 적대적 훈련 (적대적 예제를 모델 훈련에 사용하는 것)의 속도를 높이거나, 훈련된 모델의 분석에도 유용하다.
5 선형 모델들의 적대적 훈련 vs 가중치 감쇠(WEIGHT DECAY)
 [그림2] logistic regrssion에 적용된 FGSM. 이 때 이것은 근삿값이 아니라 진짜로 max-norm box에서 가장 해로운 적대적 사례이다.
[그림2] logistic regrssion에 적용된 FGSM. 이 때 이것은 근삿값이 아니라 진짜로 max-norm box에서 가장 해로운 적대적 사례이다.
a) MNIST 데이터셋에서 훈련된 logistic regression의 가중치들
b) MNIST 데이터셋에서 훈련된 logistic regression의 가중치들의 부호. 이게 최적의 교란값이다. 모델이 low-capacity(파라미터의 개수, 용량)이고 잘 적합되지만, 이런 교란은 인간이 3과 7을 혼동하게 하기 어렵다.
c) MNIST 데이터셋의 3들과 7들. logistic regression은 이 예제들을 3과 7로 분류하는 작업에서 1.6%의 에러율을 보였다.
d) FGSM으로 생성한 적대적 예제들. $\epsilon=0.25$로 하고 logistic regression에 적용하였다. 이 예제들의 logistic regression 모델의 에러율은 무려 99%이다.
우리가 실험해볼 수 있는 가장 간단한 모델은 아마도 logistic regression일 것이다. 이 경우, FGSM이 적절하다. 이 사례를 이용해 간단한 환경에서 적대적 예제가 어떻게 생성되는지에 대한 직관을 얻어보도록하자. [그림2]의 이미지들을 참조하자.
레이블 $y={-1, 1}$에서 $P(y=1)=\sigma(w\cdot x+b)$를 예측하는 단일 모델을 훈련한다고 가정하자. 이 때 $\sigma(z)$는 logistic sigmoid function이다. 훈련은 다음과 같은 경사 하강으로 구성된다.
\[\mathbb{E}_{x,y\sim p_{data}}\zeta(-y(w\cdot x+b))\]$x, y \sim p_{data}$ : true data 분포 $p_{data}$ 속의 $x, y$
$\zeta(z)=\log(1+\exp(z))$인 softplus function이다. 아래와 같이 graident sign 교란에 기반하여, 원래 $x$ 대신 $x$의 최악의 적대적 교란에서 훈련하는 간단한 수식을 유도할 수 있다. 그레디언트의 부호는 $-sign(w)$이고, $w\cdot sign(w)=||w||$ 임에 유의하라. 따라서 logistic regression의 적대적 훈련은 아래 수식을 최소화 하는 것이다.
\[\begin{align*}&\quad \ \mathbb{E}_{x,y\sim p_{data}}\zeta(-y(w\cdot \tilde{x}+b)) \\ \\ &= \mathbb{E}_{x,y\sim p_{data}}\zeta(-y(w\cdot (x-\epsilon sign(w))+b))\\ \\&=\mathbb{E}_{x,y\sim p_{data}}\zeta(y(\epsilon||w||-w\cdot x-b))\end{align*}\]$L^1$ 정규화와 다소 유사해 보인다. 그러나 중요한 차이점들이 있다. 가장 중요한것은, $L^1$ 페널티는 훈련 비용에 추가되기 보다는, 훈련 중 모델의 활성화에서 차감된다. 이는 모델이 $\zeta$를 포화시킬만큼 충분히 신뢰할 수 있는 예측을 한다면 결국엔 해당 페널티가 사라지기 시작한다는 것을 의미한다.
이것이 일어난다고는 보장할 수 없다. underfitting 체제하에서는, 적대적 훈련은 단지 underfitting을 더욱 악화시킬 뿐이다. 따라서 $L^1$ weight decay를 적대적 예제보다 더 최악의 사례라고 볼 수 있다. 왜냐하면 good margin의 경우에서는 비활성화에 실패하기 때문이다.
logistic regression을 넘어서 다중 분류 softm max regression의 경우, $L^1$ weight decay는 더욱 암울해진다. 왜냐하면 각 softmax의 출력을 독립적으로 교란될 수 있는 것으로 취급하기 때문이다. 실제로 모든 클래스의 가중치 벡터들과 맞춰서 조정할 수 있는 $\eta$를 찾을 수 없다. Weight decay는 다중 hidden states의 심층 신경망의 경우 교란으로 발생할 수 있는 손실을 과대평가한다. 이와 같이 $L^1$ weight decay는 적대로 인한 손실을 과대평가하기 때문에, feature의 정밀도보다 더 작은 $L^1$ weight decay 계수를 사용하는 것이 필수이다. MNIST 데이터셋에서 maxout network를 훈련할 때, $\epsilon=0.25$를 사용한 적대적 훈련에서 우리는 좋은 결과를 얻었다. 첫 번째 층에 $L^1$ weight decay를 적용했을 때, 0.0025의 계수조차도 너무 큰 것을 발견하였다. 또한 트레이닝 셋에서 5% 이상의 에러율을 유발하여 모델을 고착시켰다. 더 작은 weight decay 계수가 성공적인 훈련을 할 수 있게 해주지만, 정규화 효과는 없었다.
위 단락은 뭔말인지 이해할 수 없었다. 아래 원문 참조
If we move beyond logistic regression to multiclass softmax regression, $L^1$ weight decay becomes even more pessimistic, because it treats each of the softmax’s outputs as independently perturbable, when in fact it is usually not possible to find a single $\eta$ that aligns with all of the class’s weight vectors. Weight decay overestimates the damage achievable with perturbation even more in the case of a deep network with multiple hidden units. Because $L^1$ weight decay overestimates the amount of damage an adversary can do, it is necessary to use a smaller $L^1$ weight decay coefficient than the associated with the precision of our features. When training maxout networks on MNIST, we obtained good results using adversarial training with $\epsilon=.25$. When applying $L^1$ weight decay to the first layer, we found that even a coefficient of .0025 was too large, and caused the model to get stuck with over 5% error on the training set. Smaller weight decay coefficients permitted succesful training but conferred no regularization benefit.
6 신경망의 적대적 훈련
적대적 예제에 대한 취약성으로 인한 심층 신경망의 비판은 다소 오해가 있다. 얕은 선형 모델들과 달리, 심층 신경망은 적어도 적대적 교란에 대항하는 함수를 표현 할 수 있다. The universal approximator theorem (Hornik et al ., 1989)는 충분한 수의 유닛들이 있는, 적어도 하나의 hidden layer을 가지고 있는 신경망은 임의의 정확도로 어떠한 함수라도 표현할 수 있음을 보장한다. 얕은 선형 모델은 training points 부근에서 일관될 수 없는 반면, 다른 training points에서 다른 출력을 할당할 수 있다.
당연하게도, the universal approximator theorem은 훈련 알고리즘이 모든 목적에 대응하는 함수를 표현 할 수 있다고 말하지는 않았다. 명백하게, 표준적인 지도 훈련은 적대적 예제에 내성을 가지는 함수가 있다는 것을 명시하지 않는다. 이것은 따로 훈련 과정에 포함시켜야 한다.
Szegedy et al,. (2014b)는 깨끗한 예제와 적대적 예제의 혼합으로 한 훈련에서, 신경망이 다소 정규화가 될 수 있다는 것을 보였다. 적대적 예제에서 훈련시키는 것은 다른 data augmentation 방법들과는 다소 차이가 있다. 일반적으로 테스트셋에서 실제로 있을 것 같은, 번역등과 같은 변환으로 데이터를 보강(augments)한다. 이와 달리, 적대적 예제의 data augmentation은 자연적으로 발생할 것 같지 않은, 즉 모델 의사 결정 기능 방식의 결함을 파헤치는 입력을 사용한다. 기존에 이러한 과정은 벤치마크에서 drop out을 넘어서는 성능개선으로 입증된 적이 없었다. 그러나 부분적으로, 이는 L-BFGS에 기반한 고비용의 적대적 사례로 광범위하게 실험하는 것이 어렵기 때문이다.
우리는 FGSM에 기반한 아래와 같은 적대적 목적 함수가 효과적인 정규화장치라는 것을 발견했다.
\[\tilde{J}(\theta, x, y)=\alpha J(\theta, x, y)+(1-\alpha)J(\theta, x+\epsilon sign(\nabla_x J(\theta, x, y))\]우리는 모든 실험에서 $\alpha=0.5$로 설정하였다. 다른 값이 더 나을 수 있다. 우리는 이 모수에 대한 초기 설정이 충분히 잘 작동하여 더 나은 값을 찾을 필요를 느끼지 못하였다. 위와 같은 접근 방식은 현제 모델에 저항하기 위하여, 지속적으로 적대적 예제들을 갱신한다는 것을 의미한다. drop out으로 정규화된 maxout network에 이 접근 방식을 사용한 결과, 적대적 훈련을 하지 않았을 때 에러율 0.94% 에서 적대적 훈련을 했을 때 에러율 0.84%로 줄일 수 있었다.
우리는 훈련 세트의 적대적 예제에 대한 오류율이 0이 되지 않는 것을 관찰했다. 우리는 이 문제를 두 가지의 변화를 줌으로써 해결했다. 첫째로, 모델의 크기를 키웠다. 이 문제 때문에 레이어당 240개의 유닛을 사용하는 원래 maxout network대신 레이어당 1600개의 유닛을 사용하였다. 적대적 훈련이 없다면 이것은 살짝 과적합을 유발하며, 테스트셋에서 1.14%의 오류율을 얻었다. 적대적 훈련하에서, 검증 셋의 에러가 매우 느리게, 점진적으로 수평을 이루는 것을 발견했다. 기존 maxout network의 결과는 early stopping을 이용하였고, 검증 셋의 에러율이 100에폭동안 감소하지 않는다면 학습을 종료하였다. 우리는 검증셋의 에러가 매우 평평한 반면, 적대적 검증 셋은 그렇지 않다는 것을 발견하였다. 따라서 우리는 적대적 검증셋에 early stopping을 적용하였다. 훈련할 에폭의 수를 결정하기 위해 이러한 평가 기준(criterion)을 사용하였고, 60000개의 예제에 대하여 다시 훈련시켰다. 훈련 데이터의 미니 배치, 모델 가중치 초기화, drop out mask 생성에 난수 생성시를 사용한 서로 다른 seed들의 5개의 훈련에서, 테스트셋에서의 에러율은 0.77%이 4개, 나머지 하나에서 0.83%의 에러율이 나왔다. 이 0.782%의 평균은 MNIST의 순열 불변 버전에 대해 알려진 최상의 결과이다. 단, 0.79%로 DBM을 미세 조정하여 얻은 결과와 통계적으로 구별할 수 없다(Srivastata et al., 2014).
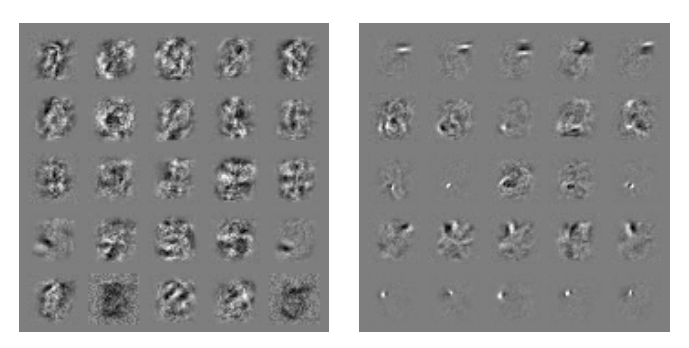 [그림 3] MNIST 데이터셋에서 훈련된 maxout network 가중치들의 시각화. 각 행은 단일 maxout 유닛의 filter를 나타낸다. 왼쪽은 일반적으로 훈련된 모델이고, 오른쪽은 적대적 훈련된 모델이다.
[그림 3] MNIST 데이터셋에서 훈련된 maxout network 가중치들의 시각화. 각 행은 단일 maxout 유닛의 filter를 나타낸다. 왼쪽은 일반적으로 훈련된 모델이고, 오른쪽은 적대적 훈련된 모델이다.
이 모델은 또한 적대적 예제에 대한 내성을 다소 가진다. 적대적 훈련없는 이러한 종류의 모델이 FGSM의 적대적 예제에서 89.4%의 에러율을 보였다는 것을 상기하자. 적대적 훈련과 함께한다면, 이 에러율이 17.9%로 떨어진다. 각각의 모델들이 생성한 적대적 예제들은 두 모델 간에 전송될 수 있지만, 적대적 훈련된 모델이 더 robustness함을 보여준다. 기존 모델을 통해 생성된 적대적 예제는 적대적 훈련 모델에서 19.6%의 에러율을 보였지만, 적대적 훈련 모델에서 생성된 적대적 예제는 기존 모델에서 40.9%의 에러율을 나타냈다. 적대적 훈련 모델이 적대적 예제를 잘못 분류할 경우, 불행하게도 그 예측은 여전히 높은 신뢰도를 갖는다. 오분류된 예제들의 평균 신뢰도는 81.4%였다. 우리는 또한 일반적으로 학습된 모델의 가중치가 적대적 훈련을 할 경우 크게 변경되며, 적대적 훈련 모델의 가중치가 상당히 더 국소화되고 해석 가능하다는 것을 발견했다(그림 3 참조).
이 적대적 훈련 과정은 데이터가 상대방(adversary)에 의해 교란되었을 때 최악의 예제의 에러를 최소화 시키는 것처럼 보일 수 있다. 이것은 학습을 하기 위해 적대적 게임을 하는 것, 또는 $U(-\epsilon, \epsilon)$ 범위의 노이즈가 섞인 샘플들을 입력에 추가했을 때 기대되는 cost의 상계를 최소화하는 것으로 해석될 수 있다. 또한 적대적 훈련은 모델이 스스로 새로운 지점에서의 레이블을 유추하는 능동적인 학습으로 볼 수 있다. 이 경우 인간 labeler는 nearby points에서 label을 복사하는 휴리스틱 labeler로 대체된다.
또한 $\epsilon$ max norm box의 모든 포인트들 혹은 box 내의 많은 점들을 샘플링하여 훈련을 실시함으로써 feature의 $\epsilon$ 정밀도 이하 변화에 둔감해지도록 정규화할 수 있다. 이는 훈련 중에 max norm $\epsilon$의 노이즈를 추가하는 것과 관련있다. 그러나, 평균과 공분산이 0인 노이즈는 적대적 예제를 예방하는 데 매우 비효율적이다. 참조된 어떠한 벡터와 해당 노이즈와의 내적의 기댓값은 0이다. 이는 많은 경우에 해당 노이즈가 더 복잡한 입력을 만들 뿐, 아무런 효과가 없다는 것을 의미한다.
실제로 대부분의 경우 이런 노이즈는 낮은 목적함숫값을 만들어낸다. 적대적 훈련은 분류에 강하게 저항하는 노이즈 포인트들을 고려함으로써 더욱 효율적으로 훈련하기 위해 노이즈가 있는 입력들에서 어려운 예제들을 마이닝 하는 것이라고 볼 수 있다. 제어 실험으로써 각 픽셀에 무작위로 $\pm \epsilon$을 하거나, $U(-\epsilon, \epsilon)$의 노이즈를 섞어서 maxout network를 훈련시켜 보았다. 이것은 신뢰도 97.3%의 신뢰도의 86.2%의 에러율을 나타내었고, FGSM으로 생성된 적대적 예제들은 신뢰도 97.8%로 90.4%의 에러율을 나타내었다.
$sign$함수의 미분이 0이거나 어디에서도 정의되지 않기 때문에, FGSM 기반 적대적 목적 함수의 경사하강법은 모델이 파라미터의 변화에 따라 상대방이 어떻게 대응할 지 예측할 수 없게 한다. 대신 작은 회전이나, scaled gradient의 덧셈을 기반으로 한 적대적 예제를 사용한다면, 교란 과정 자체가 미분가능하고 학습 과정에서 상대방에게 대응할 수 있을 것이다. 그러나, 이러한 적대적 예제는 해결하기가 어렵지 않기 때문에 정규화 시킬만큼 강력한 것을 발견하지 못했다.
하나의 자연스러운 질문은 입력을 교란하는 것이 더 나은가 혹은 hidden layer를 교란하는 것이 나은가, 아니면 둘 다 교란하는 것이 나은가이다. 여기에서는 결과과 일정하지 않다. Szegedy et al,. (2014b)는 적대적 교란은 hidden layer들에 적용됬을 때 최고의 정규화를 제공한다는 것을 보고했다. 이 결과는 sigmoidal network에서 얻어졌다. 우리의 FGSM를 사용한 실험에서 활성화가 유계이지 않은 hidden units의 network는 그들의 hidden unit 활성화를 매우 크게함으로써 단순히 반응한다는 것을 발견했다. 따라서 원래 입력에 교란을 주는 것이 일반적으로 더 낫다.
Rust 모델과 같은 saturating 모델들에서는 교란된 입력이 hidden layer의 교란과 유사하게 수행된다는 것을 발견했다. hidden layer를 회전하는 것에 기반한 교란은 유계이지 않은 활성화가 발산하여 추가적인 교란을 비교에 의해 작게 만드는 문제를 해결했다.
hidden layer의 회전 교란으로 maxout network를 성공적으로 훈련 시킬 수 있었다. 그러나 이는 input layer에 교란을 더하는 것만큼의 강력한 정규화 효과를 산출해내지 못했다. 적대적 훈련에 대한 우리의 관점은 모델이 적대적 예제에 저항하는 것을 학습할 수 있을 만한 capacity가 있을 때만 유용하다는 것이다. 이것은 universal approximator theorem이 적용되는 경우에만 선명하게 적용된다. 신경망의 마지막 layer인 linear sigmoid, linear softmax layer는 최종 hidden layer 함수에 대한 universal approximation이 아니기 때문에, 최종 hidden layer에 적대적 교란을 적용했을 때 underfitting의 문제에 직면할 수 있다. 실제로 우리는 이 효과를 발견했다. hidden layer의 교란을 사용한 훈련의 최고의 결과는 최종 hidden layer에 교란을 주지 않는다.
7 모델 CAPACITY 의 다른 종류들
적대적 예제의 존재가 직관에 맞서는 것처럼 보이는 이유 중 하나는 우리는 대부분 고차원 공간에서 거지같은 직관(poor intuitions)을 가지고 있기 때문이다. 우리는 3차원 공간에서 살고 있고, 따라서 수백개의 차원에서의 작은 변화가 더해져서 하나의 큰 효과를 발휘하는 것에 익숙하지 않다. 우리의 거지같은 직관이 미쳐 날뛰는 일이 하나 더 있다. 많은 사람들이 low-capacity의 모델들은 다양하고 신뢰도의 예측을 할 수 없을 것이라고 생각한다. 이것은 잘못된 생각이다. low capacity의 몇 모델들은 이러한 동작을 한다. 예를 들어 다음과 같은 얕은 RBF network를 사용해보자.
\[p(y=1|x)=\exp((x-\mu)\cdot \beta(x-\mu))\]이는 $\mu$ 근방에 양의 클래스가 존재한다고 높은 신뢰도로 예측할 수 있을 뿐이다. 다른 곳에서는 기본적으로 클래스가 없거나 신뢰도가 낮은 예측을 한다.
RBF network는 자신이 속았을(fooled) 때 낮은 신뢰도를 가지고 있어, 적대적 예제에 근본적으로 면역이라고 할 수 있다. hidden layer가 없는 얕은 RBF network는 MNIST 데이터셋에 $\epsilon=0.25$로 FGSM이 생성한 적대적 예제 에서 55.4%의 에러율을 보인다. 그러나, 이 모델이 오분류한 예제에서의 신뢰도가 오직 1.2%이며, 클-린한 예제에 대한 평균 신뢰도는 60.6%이다. 우리는 이러한 낮은 capacity의 모델이 공간의 모든 지점에서 올바른 답을 도출할 수 있을 것이라고 기대할 수 없다. 그러나 이것은 모델이 “이해하지 못한” 지점을 고려하여 신뢰도를 상당히 낮춰 올바른 반응을 한다.
불행히도, RBF 유닛들은 유의미한 변환에 쉽게 반응하기 때문에, 잘 일반화되지 않는다. 우리는 선형 유닛들과 RBF 유닛들을 precision-recall tradeoff 곡선의 다른 점들로 볼 수 있다. 선형 유닛들은 특정 방향의 모든 입력에서 높은 recall 을 달성하지만, 낮선 상황에 너무 예민하게 반응하여 낮은 precision을 가질 수 있다. RBF 유닛들은 공간의 특정 지점에만 반응하여 높은 precision을 달성하지만, 그렇게 함으로써 recall을 희생한다. 이러한 아이디어르 바탕으로, 우리는 심층 RBF network를 포함하여 2차(quadratic) 유닛들과 관련된 다양한 모델을 탐구하기로 결정했다. 우리는 이것이 어려운 작업이라는 것을 발견했다. 적대적 교란에 저항 할 수 있을 만큼의 2차 억제를 가진 모든 모델은 SGD로 훈련할 때 높은 훈련 셋 에러를 얻었다.
8 적대적 예제가 왜 일반화(Generalize)되는가?
적대적 예제의 흥미로운 측면은 어떠한 모델을 위해 생성된 예제가 다른 모델들에 의해 오분류된다는 점이다. 그들이 서로 다른 아키텍쳐 혹은 상호배타적인(disjoint) 트레이닝 셋에서 훈련됬을지라도 말이다. 더욱이, 이 서로 다른 모델들이 적대적 예제를 오분류할 때, 그들은 종종 그것의 클래스에 대해 서로 동의한다. 고도의 비선형성과 과적합의 기반한 설명들은 이러한 행동에 대응하지 못한다. 왜 고도의 비선형성과 넘치는 capacity를 가진 다중 분류 모델이 일반적인 분포에서 벗어난 데이터를 같은 방식으로 일관적이게 분류하는가? 이러한 행동은 적대적 예제가 실수 속의 유리수처럼 공간을 미세하게 타일링한다는 가설의 관점에서 볼 때 특히 놀라운데, 이는 적대적 예제는 일반적이지만 매우 정확한 위치에서 나타나기 때문이다.
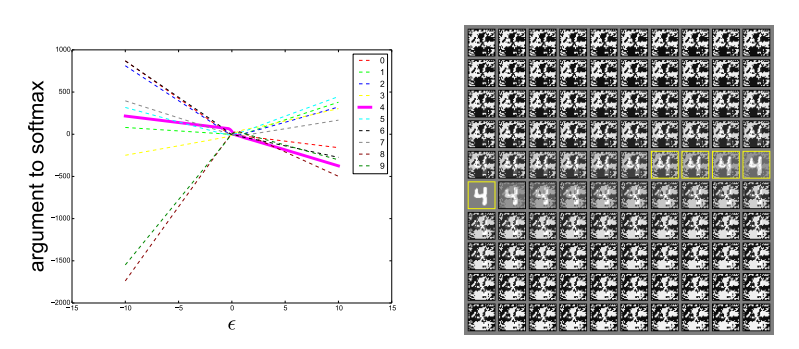 [그림 4] 다양한 값의 $\epsilon$에 따라서, 올바른 방향으로 움직인다면 $\epsilon$의 거의 모든 충분히 큰 값에 대해 적대적 예제가 안정적으로 발생한다. 올바른 분류들은 $x$가 발생하는 데이터속의 얇은 다양체안에서만 일어난다. $\mathbb{R}^n$공간의 대부분은 적대적 예제와 rubbish class 예제들로 구성되어 있다. 이 그림은 일반적으로 훈련된 maxout network로부터 만들어졌다. 왼쪽의 그림은 하나의 입력 예제에 $\epsilon$을 변화시킬 때 10개의 MNIST 클래스 각각에 대한 소프트 맥스 계층의 인수를 보여준다. 올바른 클래스는 4이다. 각 클래스에 대한 정규화되지 않은 로그 확률들은 $\epsilon$과 함께 눈에 띄게 선형이며 오분류는 $\epsilon$값의 넓은 영역에서 안정적이라는 것을 알 수 있다. 더욱이, rubbish 입력의 체제로 이동할 수 있을 만큼 충분히 $\epsilon$을 증가시킨다면 예측은 매우 극단적이게 된다. 오른쪽 그림은 곡선을 생성하는 데 사용되는 입력이다. 이 그림의 왼쪽 위는 $-\epsilon$을 사용하였고, 오른쪽 아래는 $+\epsilon$을 사용하였다. 노란색 상자는 올바르게 분류된 입력을 나타낸다.
[그림 4] 다양한 값의 $\epsilon$에 따라서, 올바른 방향으로 움직인다면 $\epsilon$의 거의 모든 충분히 큰 값에 대해 적대적 예제가 안정적으로 발생한다. 올바른 분류들은 $x$가 발생하는 데이터속의 얇은 다양체안에서만 일어난다. $\mathbb{R}^n$공간의 대부분은 적대적 예제와 rubbish class 예제들로 구성되어 있다. 이 그림은 일반적으로 훈련된 maxout network로부터 만들어졌다. 왼쪽의 그림은 하나의 입력 예제에 $\epsilon$을 변화시킬 때 10개의 MNIST 클래스 각각에 대한 소프트 맥스 계층의 인수를 보여준다. 올바른 클래스는 4이다. 각 클래스에 대한 정규화되지 않은 로그 확률들은 $\epsilon$과 함께 눈에 띄게 선형이며 오분류는 $\epsilon$값의 넓은 영역에서 안정적이라는 것을 알 수 있다. 더욱이, rubbish 입력의 체제로 이동할 수 있을 만큼 충분히 $\epsilon$을 증가시킨다면 예측은 매우 극단적이게 된다. 오른쪽 그림은 곡선을 생성하는 데 사용되는 입력이다. 이 그림의 왼쪽 위는 $-\epsilon$을 사용하였고, 오른쪽 아래는 $+\epsilon$을 사용하였다. 노란색 상자는 올바르게 분류된 입력을 나타낸다.
핑크색 실선은 올바르게 분류된 데이터의 분포이고, 다른 색의 점선들은 특정 클래스로 오분류한 적대적 예제들의 분포이다. 이외의 공간은 쓰레기 입력이다.
선형적인 관점에서 적대적 예제는 넓은 부분집합들 안에 나타난다. 방향(direction) $\eta$는 오직 비용 함수의 그레디언트와의 양의 내적을 필요로 하며, $\epsilon$은 충분한 크기만이 요구된다. [그림 4]는 이러한 현상을 보여준다. $\epsilon$의 다양한 값들을 추적함으로써, 적대적 예제가 미세한 주머니가 아닌 FGSM으로 정의된 1-D 부분 공간의 연속적인 영역에서 발생한다는 것을 알 수 있다. 이는 적대적 예제가 무수히 많으며, 왜 한 모델이 오분류한 적대적 예제를 다른 모델이 상당히 높은 확률로 오분류하는지를 보여준다.
왜 다중 분류기들이 적대적 예제들을 같은 클래스로 분류하는지를 설명하기 위해, 우리는 현재의 방법론으로 훈련된 모든 신경망이 동일한 훈련 세트에서 학습된 선형 분류기와 유사하다는 가정을 했다. 기계 학습 알고리즘이 generalize할 수 있기 때문에, 이 분류기는 훈련 세트의 다른 부분집합에 대해서 훈련하여도 거의 동일한 분류 가중치를 학습 할 수 있다. 이러한 분류기 가중치의 안정성은 적대적 예제의 안정성 또한 초래한다.
이런 가정을 시험해 보기위해, 우리는 심층 maxout network에서 적대적 예제들을 생성하였고, 이 예제들을 얕은 softmax network와 얕은 RBF network로 분류하였다. maxout network가 오분류한 예제들에서, RBF network는 maxount network가 예측한 클래스랑 16%만큼 일치한 반면, softmax network는 54.6%가 일치하였다. 그러나 이러한 수치는 모델마다 다른 에러율에 의해 크게 좌우된다. 비교되는 두 모델이 오분류하는 사례들에 주의를 기울이지 않으면, softmax regression은 maxout이 예측한 클래스랑 84.6%일치하는 반면, RBF network는 maxout이 예측한 클래스랑 오직 54.3%만이 일치했다. 비교를 위해서, RBF network는 softmax regression의 클래스를 53.6% 예측할 수 있었다. 따라서 이는 동작 속에 강한 선형 구성요소를 가지고 있다고 볼 수 있다. 우리의 가설은 maxout network의 오분류 혹은 generalize across models 하는 오분류에 대해 모든 것을 설명하지 않는다. 그러나 이 중 상당한 비율은, cross-model generalization의 주 원인이 되는 선형적 행동과 일치한다.
9 다른 가설에 대한 반박
여기서는 적대적 예제의 존재에 대한 일부 대안 가설을 고려하고 반박할 것이다.
첫째로, generative training이 훈련 과정에서 더욱 많은 제약을 줄 수 있다거나, 모델이 가짜 데이터에서 진짜를 구별하는 것을 학습하는 것을 가능하게하며 진짜 데이터에서만 높은 신뢰도를 가질 수 있게 한다는 가설이다. The MP-DPM(Goodfellow et al,. 2013a)에 이 가설을 시험할 수 있는 좋은 모델이 있다. 이 모델의 추론 과정은 미분가능하며, MNIST 데이터셋에서 좋은 분류 정확도를 얻는다. (에러율 0.88%) 추론 과정이 미분 불가능한 다른 모델은 적대적 예제를 계산하기 힘들거나, MNIST 데이터셋에서 좋은 분류 정확도를 얻기 위해 별도의 non-generative discriminator 모델을 필요로 한다. MP-DPM의 사례에서는 generative 모델 자체가 위에 있는 non-generative 분류기 모델보다 적대적인 예에 반응하고 있다는 것을 확신할 수 있다. 우리는 이 모델이 적대적 예제에 취약하다는 것을 발견했다. $\epsilon=0.25$일 때, MNIST 테스트 셋에서 생성된 적대적 예제의 에러율은 97.5%였다. 다른 형태의 generative 훈련이 내성을 가질 수 있게 한다는 것은 여전히 가능하지만, generatvie라는 사실만으로는 분명히 충분하지는 않다.
적대적 예제의 존재에 대한 다른 가설은 개별 모델이 기복이 있을지라도 여러 모델을 평균화하면 적대적 사례를 극복할 수 있다는 것이다. 이 가설을 시험해보기 위해, 우리는 MNIST 데이터셋에서 20개의 maxout network를 훈련시켜 보았다. 각각의 network는 가중치 초기화, drop out mask 생성, stochastic gradient descent를 위한 미니배치 선택을 위해 서로 다른 난수 생성 seed를 사용하였다. 이 앙상블은 전체를 교란시키도록 설계된 $\epsilon=0.25$의 적대적 예제들에서 91.1%의 에러율을 보였다. 오직 하나의 개별 모델을 교란시키도록 만들어진 적대적 예제에서는 에러율은 87.9%로 떨어진다. 따라서, 앙상블은 적대적 교란에 대해 단지 제한적인 저항만을 제공한다.
10 요약과 결론
본 문서는 다음과 같은 관찰로 요약할 수 있다.
- 적대적 예제는 고차원 내적의 성질로 설명될 수 있다. 이는 모델의 비선형성 때문이 아니라, 선형성의 의한 결과이다.
- 서로 다른 모델들에서 적대적 예제들이 일반화되는 점은 모델의 가중치 벡터의 높은 경향으로 설명된다. 서로 다른 모델일지라도 동일한 작업을 위해 훈련되었다면 유사한 함수를 학습한다.
- 공간의 특정 지점보다는 교란의 방향이 중요한다. 공간은 적대적 예제로 가득차 있는 것이 아니라, 유리수처럼 실수를 미세하게 타일링한다.
- 교란의 방향이 중요하기 때문에, 적대적 교란은 서로 다른 클-린한 입력에서 일반화될 수 있다.
- 적대적 예제를 생성하는 빠른 방법들의 종류들을 소개했다.
- 적대적 훈련이 drop out 보다 더욱 정규화를 수행한다는 것을 입증했다.
- 우리는 $L^1$ weight decay와 노이즈를 추가하는 것을 포함한 단순하지만 덜 효율적인 regularize로 제어 실험을 하여, 이들로는 적대적 훈련의 정규화를 따라잡을 수 없다는 것을 보였다.
- 최적화하기 쉬운 모델은 교란하기도 쉽다.
- 선형 모델은 적대적 교란에 저항할 능력이 부족하다. hidden layer를 사용한 구조 (the approximateor theorem이 적용된)만이 적대적 교란에 대한 내성을 학습할 수 있다.
- RBF network는 적대적 예제에 내성이다.
- 입력의 분포를 모델링하도록 훈련된 모델은 적대적 예제에 저항 할 수 없다.
- 앙상블로는 적대적 예제에 저항 할 수 없다.
rubbish class 예제와 같은 일부 추가 관찰 사항은 부록에 수록하였다.
- rubbish class 예제는 어디에나 있고 쉽게 만들 수 있다.
- 얕은 선형 모델은 이런 rubbish class에도 저항 할 수 없다.
- RBF network는 rubbish class에 저항할 수 있다.
Gradient-based optimization은 모-던 AI의 주류이다. 충분히 선형적으로 설계된 network(ReLU, maxout network, LSTM, sigmoid network that has been carefully configured not to saturate too much)는 우리가 신경쓰는 거의 대부분의 문제에 대해서, 최소한 훈련셋에서 적합할 수 있게 하였다. 적대적 예제의 존재는 데이터를 설명할 수 있거나, 테스트 데이터를 올바르게 분류하는 것이 그렇게 동작하도록 요구한 작업을 진정으로 이해하고 있지 않다는 것을 시사한다. 대신 그들의 선형적인 반응은 데이터 분포에서 나타나지 않는 지점에서 과도한 신뢰도를 보였고, 이 신뢰도의 예측은 종종 높은 부정확도를 보인다. 본 연구는 이 문제를 문제점을 명확하게 지적하고 각 문제를 수정함으로써 부분적으로 해결하였다. 그러나 어떤 이는 우리가 지금껏 사용한 모델들이 본질적으로 결함이 있다고 결론 낼 수도 있다. 최적화의 용이성은 이러한 결함으로 대가를 치르고 있다. 이는 국소적으로 안정적인 동작을 하는 모델을 훈련시킬 수 있는 최적화 과정의 개발에 동기부여를 한다.