
결정 트리는 가지(branch) 분할 을 통해 데이터를 두 개의 노드로 나눈다. 가지 분할은 예측을 만드는 리프노드까지 계속된다. 실제 예를 다뤄보면 가지가 분할되는 방법과 리프 노드가 만들어지는 방법을 쉽게 이해할 수 있다. 더 자세한 내용을 살펴보기 전에 첫 번째 결정 트리 모델을 만들어 보자.
2.1 첫 번째 결정 트리 모델
인구 조사 데이터 셋을 통해 소득이 5만 달러 이상인지 예측하는 결정 트리를 만들어보자
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
# 간편하게 받을 수 있는 인구 조사 데이터
df_census = pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data',
header=None)
df_census.columns = ['age', 'workclass', 'fnlwgt', 'education', 'education-num',
'marital-status', 'occupation', 'relationship', 'race', 'sex',
'capital-gain', 'capital-loss', 'hours-per-week',
'native-country', 'income']
df_census.drop(['education'], axis=1, inplace=True) # 일단 버려
df_census = pd.get_dummies(df_census) # 원핫 인코딩
df_census.drop(['income_ <=50K'], axis=1, inplace=True) # 타깃이 쪼개졌으므로 하나 지워준다
# feature와 target을 분리해줘야 한다
X = df_census.iloc[:, :-1]
y = df_census.iloc[:, -1]
train_test_split() 함수를 임포트하고 데이터를 훈련과 테스트 데이터 쌍으로 분리해준다. 할 때마다 결과가 달라지는 건 싫으니까 random_state도 아무거나 박아준다
1
2
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=1117)
그 다음 일반적인 단계에 따라 결정트리 분류기를 만들어준다. 여기서 accuracy_score() 는 정확하게 맞은 예측 횟수를 전체 예측 횟수로 나눈 값을 반환한다. 20개 예측 중에 19개가 맞았다면 accuracy_score() 함수는 95%를 반환한다
1
2
3
4
5
6
7
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
clf = DecisionTreeClassifier(random_state=1117) # 1.모델 생성
clf.fit(X_train, y_train) # 2.훈련
y_pred = clf.predict(X_test) # 3.예측
accuracy_score(y_pred, y_test) # 4. 평가
2.2 결정 트리의 작동 원리
결정트리의 내부 작동 방식은 그림으로 잘 나타낼 수 있다.
1
2
3
4
5
6
7
8
9
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
plt.figure(figsize=(13, 8))
plot_tree(clf, max_depth=2, # max_depth 설정 안 해주면 밑도 끝도 없이 그린다
feature_names=list(X.columns),
class_names=['0', '1'], filled=True,
rounded=True, fontsize=10)
plt.show()
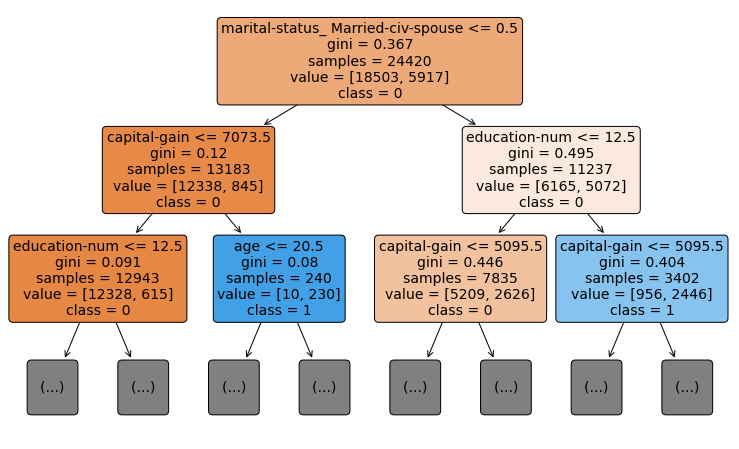 위에서 사용한 모델에서 맨위 2개층
위에서 사용한 모델에서 맨위 2개층
맨 위가 루트노드이다. 맨 위/ 맨 아래를 제외한 모든 사각형이 노드이다.
지니 불순도 (gini impurity)
노드의 두 번째 줄은 gini=x.xxx 이다. 이 값을 지니불순도라고 하며 결정 트리가 어떻게 분할할지 결정하는데 사용된다. 불순도 값이 가장 낮은 분할을 찾는 것이 목표이다. 지니 불순도가 0이면 하나의 클래스로만 이루어진 노드이다. 지니 불순도가 0이면 노드안 클래스별 샘플갯수가 동일한것이다. 0에 가까울 수록 좋다.
지니 불순도를 계산하는 식은 다음과 같다.
\[gini=\sum_{i=1}^c(p_i)^2\]여기서 $p_i$는 전체 샘플 중에서 해당 클래스 샘플의 비율이고, $c$는 총 클래스 가짓수이다. 이 예시에서 $c=2$.
스텀프 (stump)
딱 한번만 분할된 트리를 스텀프라고 한다. 스텀프 자체는 강력한 모델이 아니지만 부스터로 사용되면 강력해질 수 있다.