
이름에서 알 수 있듯이 BERT는 트랜스포머 모델을 기반으로 하며, 인코더-디코더가 있는 트랜스포머 모델과 달리 인코더만 사용한다.
1장에서 문장을 트랜스포머 인코더에 입력하고 문장의 각 단어에 대한 표현 벡터를 출력으로 반환한다는 것을 확인했다. 그럼, 양방향 (Bidirectional)이라는 단어는 무엇을 의미할까?
트랜스포머 인코더는 원래 양방향으로 문장을 읽을 수 있기 때문에 양방향이다. 따라서 BERT는 기본적으로 트랜스포머에서 얻은 양방향 인코더 표현이다.
예제를 통해 BERT가 어떻게 트랜스포머에서 양방향 인코더 표현을 하는지 이전 절에서 살펴본 문장으로 이해해보자.
“He got bit by Python” 이라는 문장 A를 트랜스포머에 입력으로 제공하고 문장의 각 단어에 대한 문맥 표현 (임베딩)을 출력으로 가져온다. 인코더에 문장을 입력하면 인코더는 멀티 헤드 어텐션 메커니즘을 사용해 문장의 각 단어의 문맥을 이해해 문장에 있는 각 단어의 문맥 표현을 출력으로 반환한다.
[그림 2-3]과 같이 문장을 트랜스포머 인코더에 입력으로 제공하고 문장의 각 단어를 출력으로 표시했다. 그림과 같이 N개의 인코더를 쌓을 수 있으나, 불필요한 복잡함을 줄이기 위해 하나의 블록만 확장했다. [그림 2-3]에서 “파이썬”이라는 단어의 표현을 출력하고 차례로 “그(the)”라는 단어의 표현을 출력한다. 각 토큰의 표현 크기는 인코더 레이어의 출력의 차원이며, 인코더 레이어의 차원이 768이라고 가정하면 각 토큰의 표현 크기는 768이 된다.
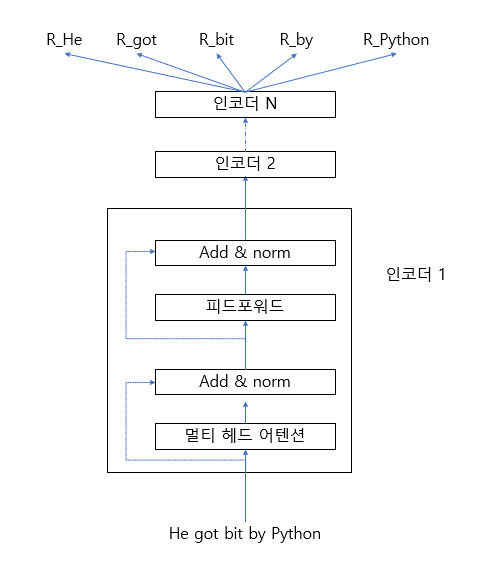 그림 2-3 BERT에 입력된 A 문장의 각 단어 표현 출력
그림 2-3 BERT에 입력된 A 문장의 각 단어 표현 출력
마찬가지로 , “Python is my favorite programming language”라는 B 문장을 트랜스포머 인코더에 입력하면 그[그림 2-4]와 같이 문장의 각 단어에 대한 문맥 표현을 얻을 수 있다.
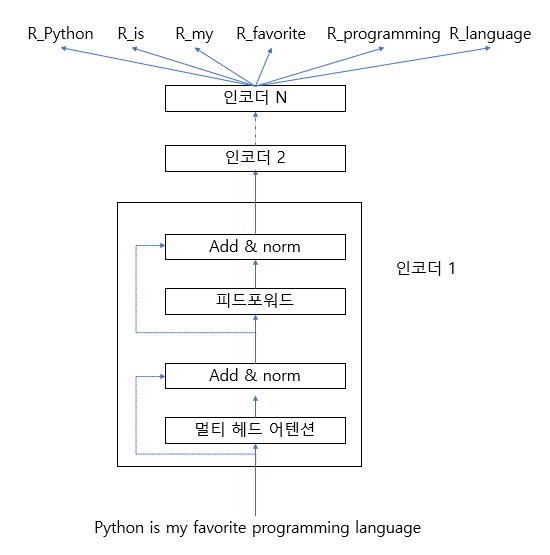 그림 2-4 BERT에 입력된 B 문장의 각 단어 표현 출력
그림 2-4 BERT에 입력된 B 문장의 각 단어 표현 출력