
앙상블 모델이 개별 머신러닝 모델보다 뛰어난 이유를 알아본다. 또한 배깅이 뭔지 알아보자. 둘 모두 랜덤포레스트의 핵심이올시다.
1.1 앙상블 방법
머신러닝에서 앙상블 방법은 개별 모델의 예측을 합치는 머신러닝 모델을 말한다. 앙상블 방법이 여러 모델의 결과를 연결하기 때문에 오차를 줄이고 더 나은 성능을 내는 경향이 있다.
어떤 집이 시장에 나온 첫 달만에 팔릴지 예측한다고 가정하자. 여러 개의 머신러닝 모델을 실행하여 로지스틱 회귀는 80% 정확도, 결정 트리는 75% 정확도, k-최근접 이웃(K-nearest neighbors) 은 77% 정확도를 얻었다.
가장 정확한 모델인 로지스틱 회귀를 최종 모델로 정할 수 있다. 그러나 더 나은 방법은 각 모델의 예측을 합치는 것이다.
분류기의 경우 앙상블하는 대표적인 방법은 다수결 투표(majority vote) 이다. 세 모델 중 적어도 두개가 첫 번째 달에 집이 팔린다고 예측하면 최종 예측이 Yes 그렇지 않으면 No가 된다.
전체적인 정확도는 앙상블 방법을 사용할 때 일반적으로 더 높다. 앙상블에서는 예측이 틀릴려면 한 모델이 틀리는 것으로는 충분하지 않다. 즉 다수의 분류기가 틀려야 한다.
앙상블 방법은 크게 두 가지로 나뉜다. 첫 번째는 사이킷런의 VotingClassfier 처럼 사용자가 선택한 여러 종류의 머신러닝 모델을 연결하는 방식이다. 두 번쨰는 XGBoost나 랜덤 포레스트 처럼 같은 종류의 모델을 여러개 합치는 앙상블이다.
랜덤 포레스트는 모든 앙상블 방법 중에서 가장 인기 있고 널리 사용되는 알고리즘이다. 랜덤 포레스트의 개별 모델은 결정 트리이다. 랜덤 포레스트는 최종 예측을 만들기 위해 수백 또는 수천 개의 결정 트리로 구성될 수 있다.
랜덤 포레스트는 분류일 경우 다수결 투표를 사용하고 회귀일 경우 모델의 예측을 평균하지만 개별 트리를 만들기 위해 부트스트랩 애그리게이션(bootstrap aggregation) 의 약자인 배깅 이란 특별한 방법을 사용한다.
1.2 배깅 (Bagging)
부트스트래핑(bootstraping)은 중복을 허용한 샘플링을 의미한다.
2N개의 색 구슬이 들어 있는 가방이 있다. 한 번에 하나씩 N개의 구슬을 선택하려고 한다. 구슬을 선택할 때마다 이를 가방에 다시 넣는다. 아주 운이 나쁘면 동일한 구슬을 10번 선택할 수도 있다.
어떤 구슬은 한 번 선택하게 되고 어떤 구슬은 전혀 선택하지 않을 수도 있다.
다음은 N개의 구슬을 선택하는 예시이다.
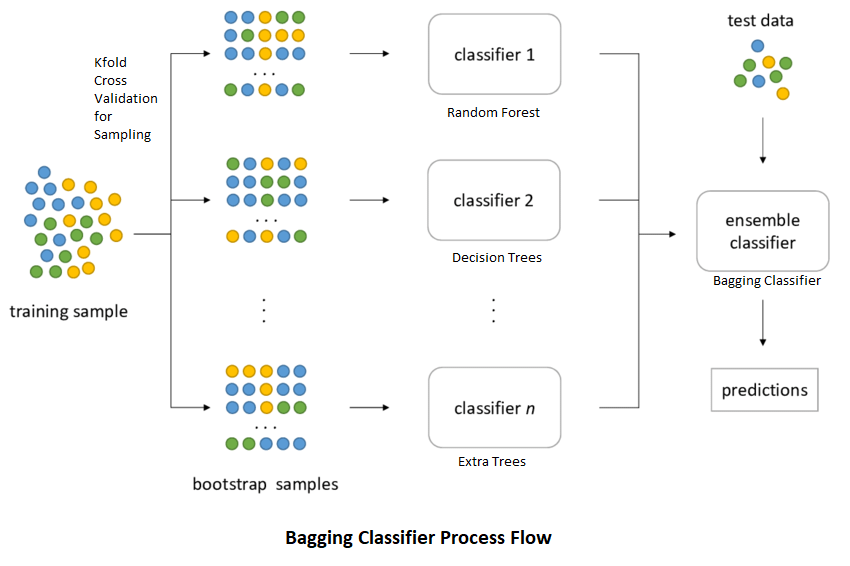
위 그림에서 볼 수 있듯이 부트스트랩 샘플은 중복을 허용한 샘플링으로 만든다. 즉, 같은 샘플을 한 부트스트랩 샘플에 여러번 넣을 수 있다는 소리이다.
랜덤 포레스트는 부트스트래핑을 사용한다. 개별 결정 트리를 만들 때 부트스트래핑을 수행한다. 모든 결정 트리가 동일한 샘플로 만들어진다면 모두 비슷한 예측을 만들게 되고 앙상블한 결과도 개별 트리와 비슷해 질 것이다. 랜덤 포레스트는 원본 데이터셋과 같은 크기의 부트스트래핑 샘플 을 사용해 각 트리를 만든다. 수학적으로 계산하면 평균적으로 각 트리의 샘플은 전체 샘플의 2/3을 포함하며 1/3은 중복된 샘플이다.
부트스트래핑 단계 후에 각 결정 트리는 자신만의 예측을 만든다. 이 트리의 예측을 모아서 최종예측을 만든다. 분류일 경우 다수결 투표를 사용하고 회귀일 경우 평균을 낸다.
요약하면 랜덤 포레스트는 부트스트래핑을 사용한 결정 트리의 예측을 합치는 것이다. 이러한 앙상블 방법을 배깅이라고 한다.